Cardimom: A Twitter Bot
This post is about Cardimom, a Twitter Bot that tweets interesting posts related to JavaScript and TypeScript!
Scope
This project is designed to tweet new posts published by a given set of blogs. This project is inspired from Planet Clojure which tweets new posts on topics related to Clojure that are published by a certain set of approved blogs.
Here’s how new posts get published by the Twitter bot, Cardimom. First, relevant details of a blog need to be added to the project’s config file, namely blog_spec.json. These details include: the link to the feed of the blog, the Twitter username of the author, and relevant filtering logic (discussed below).
Once a blog has been added to the config file, the system will parse the blog feed periodically and tweet any new post(s) published by that blog. To this end, a post will be considered to be a ‘new post’ if it was published after the most recent post tweeted by Cardimom.
Here’s an example of a post that was tweeted by the Cardimom:
New blog post by @Microsoft: Announcing TypeScript 4.5 Beta https://t.co/roOwQW8Alt
— cardimom (@cardimomT) October 2, 2021
Config
The config file contains the list of all the blogs that will be tracked by the system. To add a new blog, a pull request will need to be made to the config file, namely blog_spec.json. Each entry of the config file relates to a specific blog and it should contain the following properties:
- link: This property should contain the URL to the feed of the blog.
- filter: This property should contain another JSON object. This object should have the following two properties:
includes_anyandexcludes_all. Each of these properties should contain an array of key-words. For a blog-post to be selected by the system (for tweeting), the contents of that post or the title of the post should contain at least any one of the key-words included in theincludes_anyarray and should not contain any of the key-words mentioned in theexcludes_allarray. It is, however, permissible to have either or both of these arrays to be empty. If any of these arrays is empty, the relevant filter logic (inclusion or exclusion, as the case may be) will be deemed to be fulfilled. - twitter_username: This property should contain the Twitter username of the author of the blog.
Blogs on JavaScript and TypeScript
The purpose of this project is to create a Twitter bot that shares blog-posts related to JavaScript and TypeScript. To this end, it is encouraged that any contributor wishing to add their blog to the config file, should add (at the least) the keywords JavaScript, NodeJs and TypeScript to the includes_all list. Contributors are permitted to add other related key-words as well.
System Design
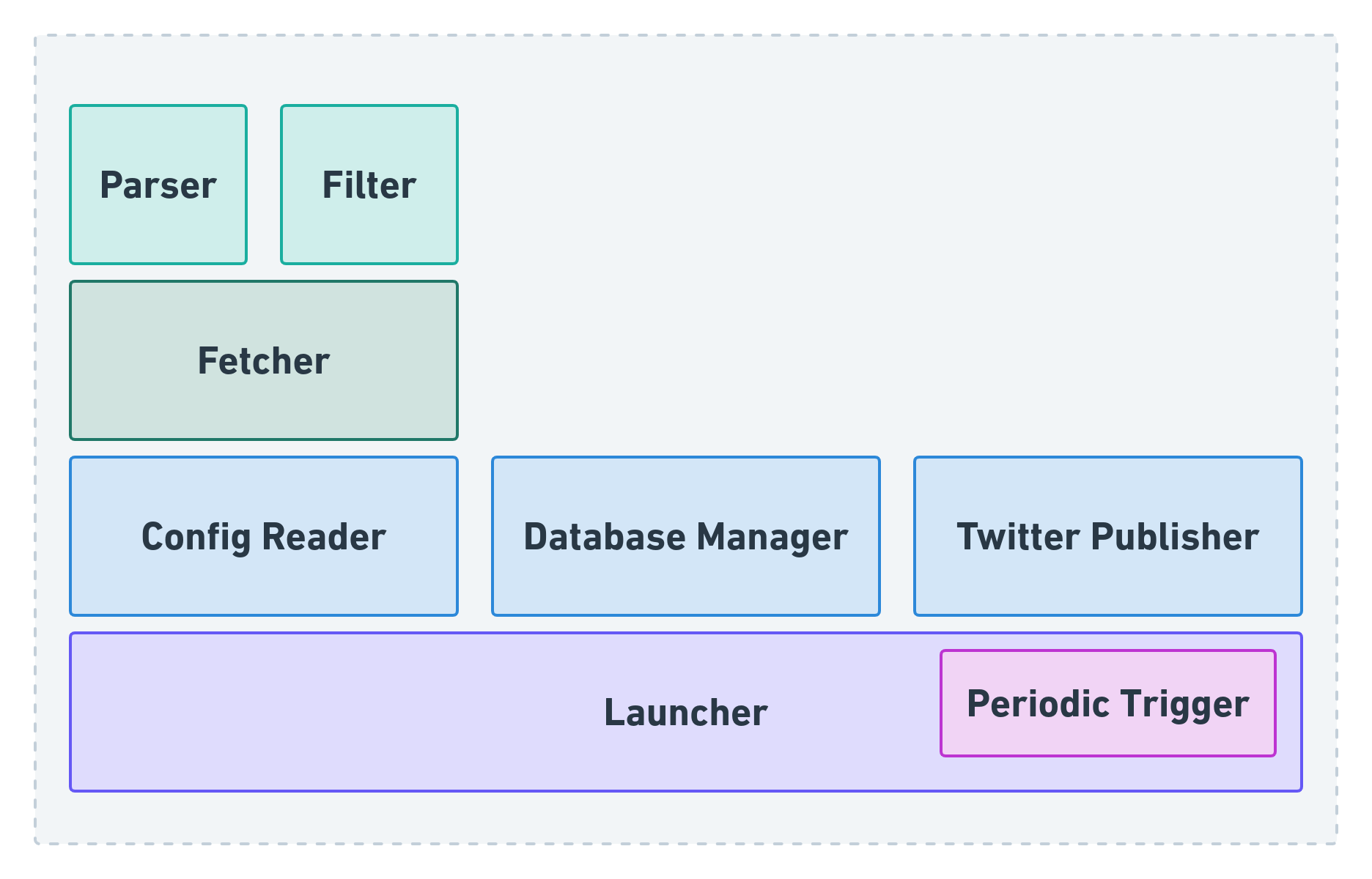
Launcher: This module triggers the system. It is run periodically, after every 60 minutes.
Config Reader: It parses the config file and returns a list of all the (valid) blogs from the config file.
Database Manager: It connects with the database maintaining the state of the project.
Parser: It parses each blog feed and extracts the necessary details of each post published by that blog, namely, the title of the post, the date of publication, the contents of the post, and the link to the post.
Filter: It filters out the posts published by each blog which fail to meet the relevant filter logic (inclusion and exclusion of key-words).
Fetcher: It fetches the list of all the previously unpublished posts of every blog.
Twitter Publisher: It handles the tweeting of new posts published by each blog, on behalf of the Cardimom Twitter account. This is done by accessing the Twitter REST API’s /status endpoint.
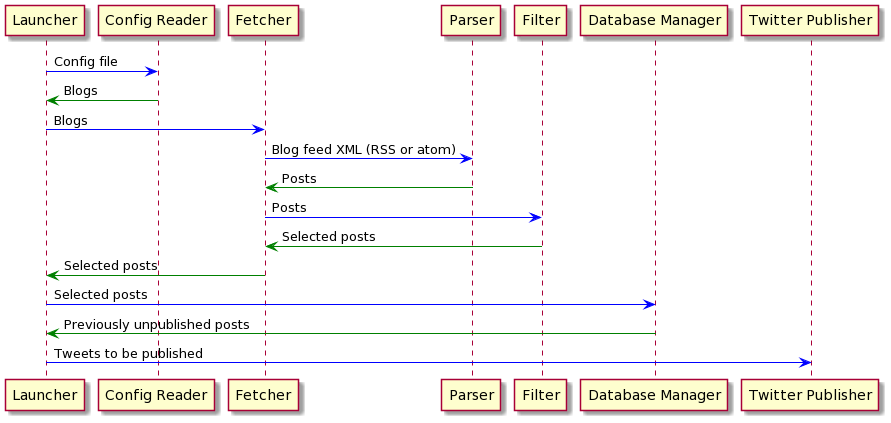
The following sequence diagram provides a more detailed description of how the control flows through the system:
Database Schema
The system remains connected to a database, which maintains the list of all the posts that were earlier fetched and tweeted by the system. This ensures that during each run, the system can rely on the contents of the database to determine if a particular post should be fetched, in accordance with design goals of the system (see below).
To maintain the state of the project, the database should maintain a table containing the following four columns:
link: To store the ‘link’ property of each postauthor: To store the ‘author’ property of each postposted_at: The timestamp when each post is added to the databasepublished_at: The publication timestamp of the post (on the blog).
In this project, the database schema (called posts) was created by using PostgreSQL. Here’s the structure of the database schema:
Column | Type | Collation | Nullable | Default
--------------+--------------------------+-----------+----------+---------
link | text | | not null |
author | text | | not null |
posted_at | timestamp with time zone | | |
published_at | timestamp with time zone | | |
Indexes:
"posts_pkey" PRIMARY KEY, btree (link)
Content Aggregation Logic
The system expects blog feeds to be in either of the two standardised formats of web feed: RSS and atom. If a blog feed does not conform to the requisite specifications of either of these two formats, the system will reject that feed. Thus, it is important that blog-feeds adhere to the specification requirements of RSS and atom.
Each feed contains a list of items (called ‘items’ for RSS and ‘entries’ for atom), each with a set of extensible meta-data (such as title, date of publication, link etc). In the case of blogs, each of these items represent a post published by that blog.
Depending on the format of a given blog feed, the relevant details of each post can be extracted from the elements of each item, by using the standard DOM parsing API. For example, in the case for an RSS feed, the window.document.getElementsByTagName("item") returns the list of all items (i.e., post objects). Now, the getElementsByTagName function can again be used on each post object, to extract the element with a particular tag (such as the date of publication). Finally, the innerHTML property of that element so extracted will provide its text version.
Here’s an illustration for extracting the date of publication of the first post object from an RSS feed:
let listOfItems = window.document.getElementsByTagName("item");
let firstPost = listOfItems[0];
let dateOfFirstPost = firstPost.getElementsByTagName("pubDate")[0].innerHTML;
For the purpose of this project, the following meta-data needs to be fetched from each post published by every blog: title of the post, the date of publication, the contents of the post, and the link to the post. In the case of an RSS feed, the corresponding elements are fetched in this regard: title, pubDate, description/ content:encoded, and link. Similarly, for atom feeds, the following elements are fetched: title, published / updated, content, and content / summary.
Note that, the getElementByTagName returns an array of all elements with a given tag name. In an RSS or atom feed, each post object will contain only one element for the tags relating to its title, date of publication, link, content. So we need to only extract the first element of each tag.
Design Goals
The project is designed to ensure that no post gets tweeted more than once. In other words, the design goal of the project is that each post should be published at most once. To ensure this, an idempotency check is conducted, before tweeting a new post. To this end, the following steps are undertaken:
- Aggregation of new posts (timestamp based): Only posts that are published after the timestamp of the most recently published post that was tweeted by the Twitter bot, is fetched by the system. This ensures that only ‘new posts’, i.e., posts published after to the most recent post tweeted by the bot will be considered by the system during each run. This is implemented by fetching the most recent timestamp from the
posted_atcolumn from the database schema. - Determining unique posts (link based): The date of publication of an existing post can be updated in a feed in the future. This can happen, for example, if an existing post is modified and the date of updation is maintained as the date of publication on the blog feed. Thus, merely selecting ‘new posts’ will not prevent posts from being tweeted more than once. Thus, the system selects only ‘new and unique’ posts. As links can act as unique identifiers to specific posts, the link of each ‘new post’, is checked with the existing values in the
linkscolumn of the database schema. The presence of the link of any ‘new post’ in the database would indicate duplication of posts - Failure handing to ensure at-most once semantics (update database before publishing): The list of ‘new and unique’ posts are added to the database schema, before passing them to the Twitter module. This means that, if there is any failure while tweeting the new posts, the project will treat them as ‘old posts’ and they will be ignored in the next round of system run. This ensures the at-most guarantee of the system.
Note that, for the very first system run, the database would be empty and potentially every post would be considered as ‘new and unique’ posts. This may produce undesirable results, as the system will try to tweet every single post published by the blogs mentioned in the config file. To prevent this, a cut-off timestamp has been provided (January 1, 2021 00:00:00 UTC + 5:30), when the database is empty. The system will only tweet posts that are published after this cut-off timestamp.
The system runs periodically, every 60 minutes. During each run, the system filters out the list of each new and unique post and proceeds to tweet them. The fairly large interval between consecutive system runs was chosen keeping in mind Twitter’s rate limits.
Deployment and Testing
The project is deployed on Heroku. Heroku provides a developer-friendly platform for deploying and managing applications on the cloud. Once deployed, Heroku packages the source code of the application along with its dependencies into virtual containers (called ‘dynos’), which are responsible for executing the code of the application in the relevant run-time environment.
Need for deployment to Heroku
By virtue of the nature of the project, the system needs to be executed in real-time (subject to periodic intervals). Unlike the earlier project implementing a simplified version of Lisp, the present project requires the system to consistently check for new blog posts from time to time. Given this requirement, it would be difficult to reliably deploy the project locally (i.e., on a local machine), as the execution of the project would be crucially dependent on the state of the local machine for an indefinite period of time. In fact, to reliably deploy the project locally, one will need substantial allocation of resources (to prevent any future break in connectivity, failure of the local machine etc.). This is difficult to achieve on a small-scale. Thus, to avoid such road-blocks, this project is deployed on a cloud-based platform (namely, Heroku) which will offer a virtual container to consistently execute the project and maintain its database.
Secrets Management
To connect to Twitter and the database, we need to have certain shared secrets (e.g. password). But this cannot be part of the code, as it would be openly accessible (for example, on GitHub). Therefore the standard practice of exposing secrets through environment variables has been used in this project. To run the system locally, we can use shell environment variables. On Heroku, environment variables were exposed using the web UI, ensuring that the code on GitHub does not reveal secrets.
System Testing
The project implements system-wide tests (as opposed to unit tests for each module). This means that the test module will work with a sample config file and run the entire system to check if the system is producing the expected results (as opposed to testing each module separately). This was mostly done in the interest of time.
System testing was done using GitHub Actions, which allows automated integration tests to be run during every time a new commit is pushed or a pull-request is received. Given that GitHub Actions provides for continuous integration, the GitHub workflow is configured to automatically build the application, deploy it on GitHub-hosted virtual machines, set up a database and run integration tests during each commit. Thus, once each commit is pushed to the main branch, the project gets deployed momentarily, on GitHub’s containers, specifically to run tests.
- Empty database test: This is done by erasing the contents of a given database and running the system with a set of sample blog feeds. Instead of tweeting the posts during each run, the test module returns the list of posts that would have been tweeted. The contents of this list is checked to ensure that the system is working correctly.
- Testing with new posts: This test is run to check if a new and unique post is correctly fetched by the system. This is done by erasing the most recent post from the database. Now, when the system is run, the test module should return a list containing only the post that was deleted earlier.
- Idempotency test: This test is conducted to ensure that consecutive system runs with the same set of blog feeds do not produce different results. During consecutive system runs, the list of ‘new and unique’ posts should be empty, as the very first run should have fetched them and added them to the database. Thus, during an idempotency test, it is checked if the list of posts returned by the test module is an empty one.
Limitations
Here are some of the major limitations, arising out of the design of the project:
-
System-wide cursor: The determination of whether a post is considered to be a ‘new’ post (therefore due for publication on Twitter), is based on the latest timestamp retrieved from the database. As the system does not carry out this check at the level of each blog, it is possible that the system may skip certain posts that carry an older timestamp than the latest timestamp available on the database. This can happen if, for example, a blog sets a default timestamp (eg. midnight) for its posts. This limitation has since been rectified, by using blog-level cursors.
- Rate limitations: If, during any cycle of execution, the Cardimom Twitter account hits Twitter’s rate limit, some of the posts (due for publication during that cycle) will not be published on Twitter. However, the system will deem them as having been published (as the database will contain all those posts). Thus, the system currently does not provide for an effective handling of unpublished tweets, caused due to Twitter’s rate-limitations.
- XML format: The system only supports feeds that are generated in XML format. Further, as noted above, the system will not be able to parse feeds that do not comply with the corresponding specifications of either RSS or atom.
-
Length of each tweet: For each new blog-post, the system builds a tweet in the following format:
New blog post by ${post.twitter_username}: ${post.title} ${post.link}. Thus, for example, for the post on hash tables published earlier on this Blog, the system published the following tweet:New blog post by @oteecodes: Hash Tables https://t.co/3zCQb2LBqD
— cardimom (@cardimomT) October 1, 2021If, however, for a given post, the length of the tweet exceeds Twitter’s 280-character limit, the system builds a truncated alternative version of the tweet, in the following manner:
${post.twitter_username} posted ${post.link}. For example, for this post (with a relatively long URL: “https://decentralizedthoughts.github.io/2021-10-04-crusader-agreement-with-dollars-slash-leq-1-slash-3$-error-is-impossible-for-$n-slash-leq-3f$-if-the-adversary-can-simulate/”), the system published the following tweet:@ittaia posted https://t.co/bU92rff8cq
— cardimom (@cardimomT) October 4, 2021If the length of the tweet still exceeds the 280-character limit, the system will skip that post, instead of truncating its length any further, or dividing it into multiple threads. Thus, it is expected that, for some posts, the system will fail to publish a tweet, owing to size restrictions.
- Filter logic: The system applies the filter logic (both exclusion and inclusion of keywords) on the content of each post, as available on the respective feed. It does not fetch the contents of the post from the respective URL. Thus, if the feed of a blog provides a truncated version of the contents of that post, the filter logic will be applied only on that truncated version.
Latest Tweet
Here’s the latest tweet published by Cardimom: