Event and Processing Time Semantics in Blog Aggregators
One of the identified limitations of the Cardimom Twitter Bot was that it maintained a system-wide cursor for fetching posts. This means that if the publication timestamp of a new post happens to be earlier than the timestamp when the system last published a tweet, it will ignore that new post. This post discusses how this limitation has been rectified in the project.
The problem
Recall that a post would be deemed to be ‘new’ by the system if it was published after the timestamp of when the most recent tweet was published by the system. For example, if the system publishes a tweet on 10:00:01 of a given day, it will consider every post bearing a publication timestamp later than 10:00:01. Note that the ‘publication timestamp’ of a post is fetched from the feed of its blog.
Now, the limitation is that this logic may inadvertently leave out some new posts.
- Publication of posts may be dependent on other posts: If a post is published on a back-dated timestamp(say, mid-night), whether the system will tweet that post, will be dependent on the other posts seen by the system. It will publish that post, if its timestamp is later than the timestamp when the system last published a tweet. Otherwise, the post will not be considered as a ‘new post’ by the system.
- The delay caused during each system run may result in skipping of posts: As the number of blogs grows, it would take longer to complete each system run. If a post is published during this period, the system may not pick that post. This can happen if, after the system has fetched the blog feed of a blog, a new post is published by that blog. Ideally, the system would pick this post during its subsequent run. However, this may not be the case, if the latest timestamp recorded by the system during that very system run is greater than the publication timestamp of that post.
To rectify this, we need to use a better logic that can somehow decouple the timestamp when the system last posted a last tweet from the timestamp mentioned on each blog feed.
Event Time and Processing Time
Event time refers to the timestamp when an event actually occurs in the real world. In the present project, the timestamp of publication (as mentioned on the respective blog feed) is the event time. Event time is independent of the timestamps maintained by the system.
Processing time refers to the timestamp when an event was seen (or processed) by the system. In this case, the timestamp when the system fetches a post will be considered as processing time.
Out of Order Events
As our system is set to run periodically (hourly basis), there will always be a difference between the event time and the processing time. But if the system was set to run consistently without any breaks, ideally the event time and processing time would closely correspond to each other. (The only difference will be for the time taken by the system to complete each run).
However, in practice, this is often not the case. There is often a significant lag between when the system sees an event and when the event actually occurred. Such events are called out of order events, that is, the order in which events occur and the order in which they are observed by the system differs. As indicated above, this kind of lag can happen due to default timestamps set by a blog feed. There could be multiple other practical reasons that may cause this delay: loss of connectivity, outage, sudden spike in data rates, or “just bad luck”.
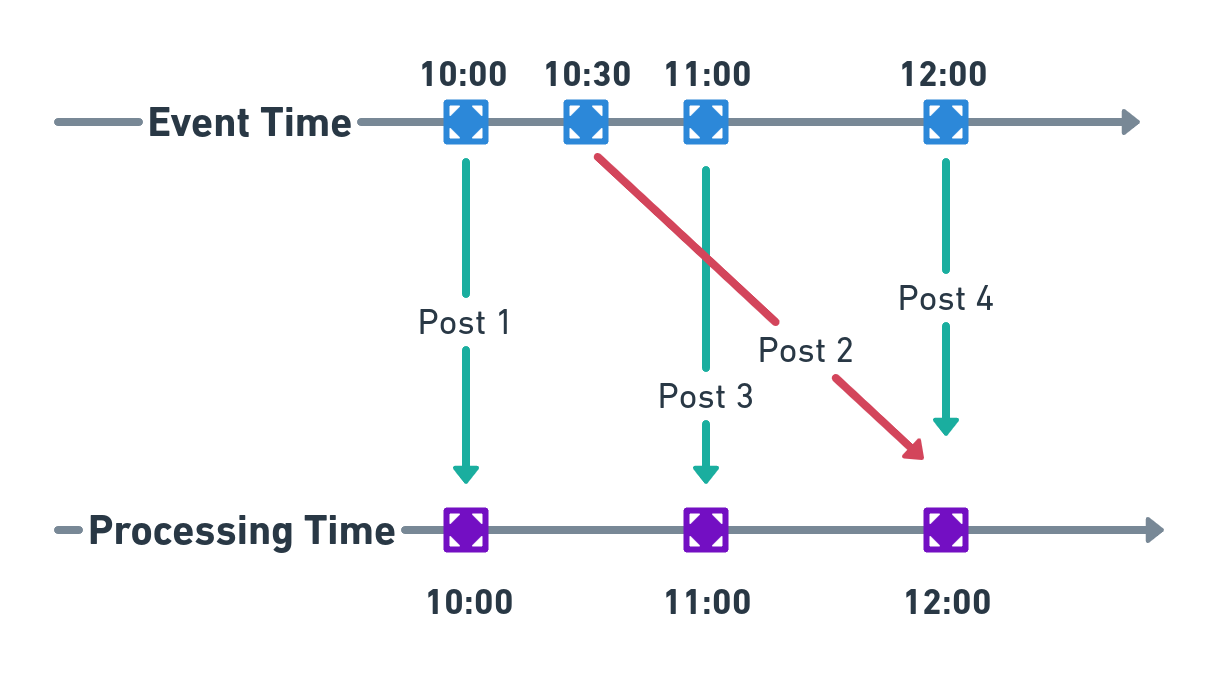
To illustrate how this lag can cause inadvertent missing out of new posts, consider the following diagram. For posts 1, 3 and 4, the system fetches the posts without any lags (i.e., the event time and the processing time are the same). Thus, all these posts are fetched for publication. However, for some reason, the system fails to fetch post 2 (published at 10:30) during the respective system run (11:00). Instead, this post is seen in the next system run at 12:00. As post 3 was already published at 11:00, post 2 gets skipped, as the system considers it to be an old post.
To illustrate this further, let’s take a few examples of out of order events. For the sake of simplicity, let’s assume the system runs consistently, without any intervals.
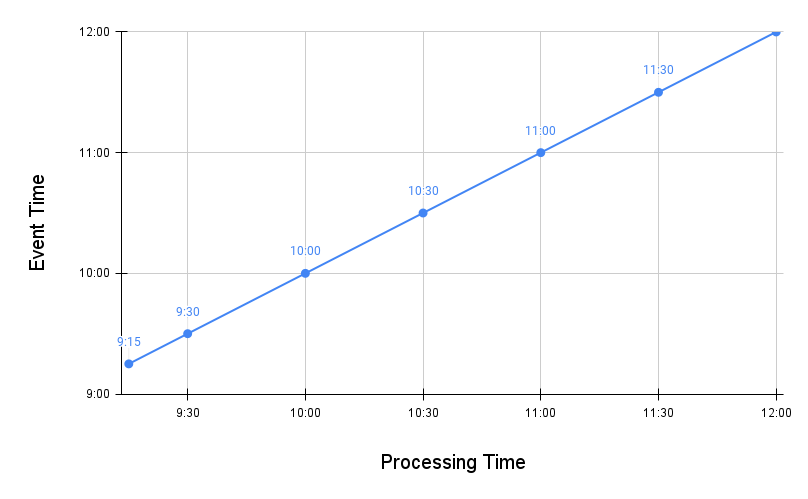
Before dealing with out of order events, note that every in-order event will always be fetched by the system. In the graph below, every event on the blue diagonal signifies in-order events, i.e., where the event time and processing time are one and the same. This is the ideal case.
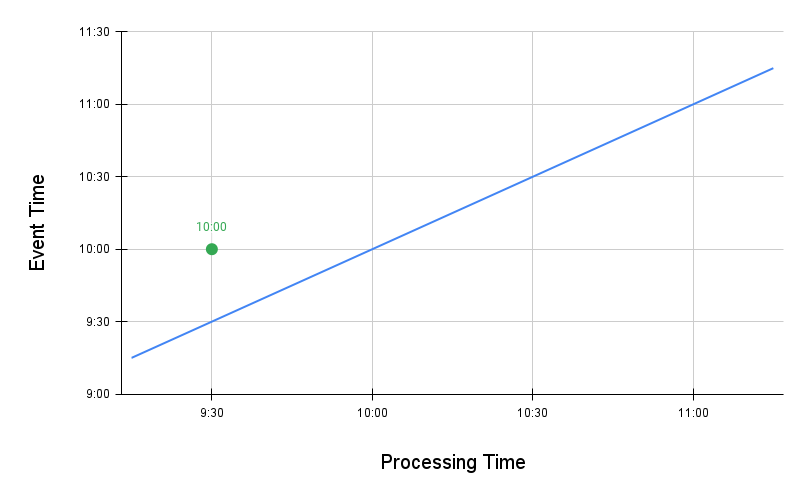
Now, let’s take the example of a post that bears a timestamp ahead of the processing timestamp. Say, the processing timestamp is 10:00 and the event timestamp is 09:30. This post will get fetched, as it’s timestamp will be greater than every previous timestamp when the system was run. In the graph below, the green dot refers to this out of order event.
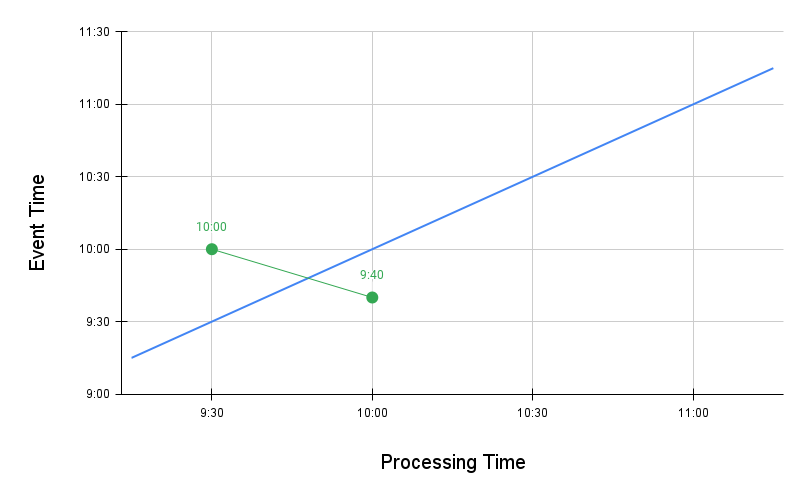
Now, let’s take the example of a post that was published earlier than the current processing timestamp. Say, the processing timestamp is 10:00 and the event timestamp is 09:40. This post will also be fetched, as the processing timestamp when the most recent post was fetched (09:30) is earlier than the event timestamp of the current post. In the following graph, the green line signifies the timestamps of this post and the earlier post.
Now, let’s say the system has progressed further and the last processing timestamp when a post was published is 11:30. Say, during a subsequent system run (at 12:00), a post is encountered with an event timestamp of 10:45. Now, this post will not get published, as it’s event timestamp is earlier than the processing timestamp when the system last published a post.
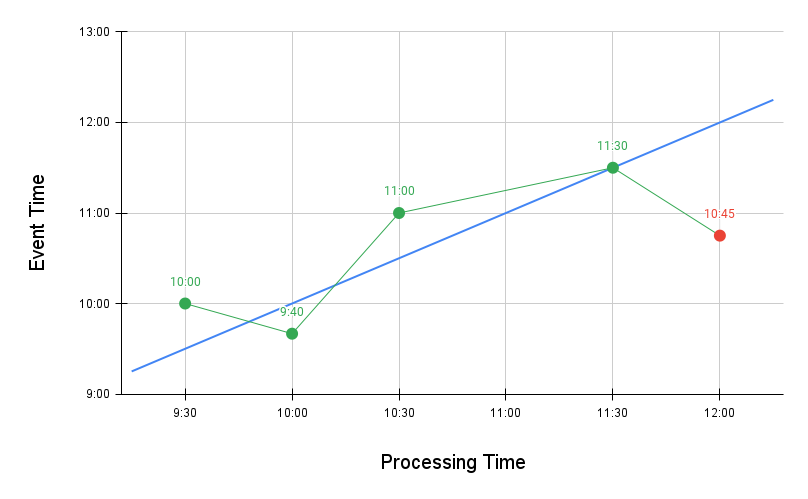
From the above, three conclusions can be drawn:
-
First, the system will always fetch in order events.
-
Second, the system will always fetch out of order events which have a timestamp in the future (i.e., greater than the current processing timestamp).
-
Third, whether an out of order event bearing a timestamp earlier than the current processing timestamp will be published or not, will be dependent on the processing timestamp when the system last published a post. This makes the system non-deterministic when it comes to such posts.
Decoupling event time and processing time
To reduce the lack of certainty with respect to out of order events, the system should decouple event time from processing time. This would mean that the system should avoid relying on system-wide cursors to determine if a post is ‘new’ (and therefore, due for publication). Instead, it should maintain a blog-level cursor: a post will be considered a ‘new’ post, if it bears a timestamp (event time) that is greater than the timestamp of the last post of that blog.
Earlier, the system would select a new post, if the post bore a timestamp greater than the timestamp returned from the following query :
--posted_at refers to the processing time of the posts
select max(posted_at) from posts;
When the posts table contains the following entries:
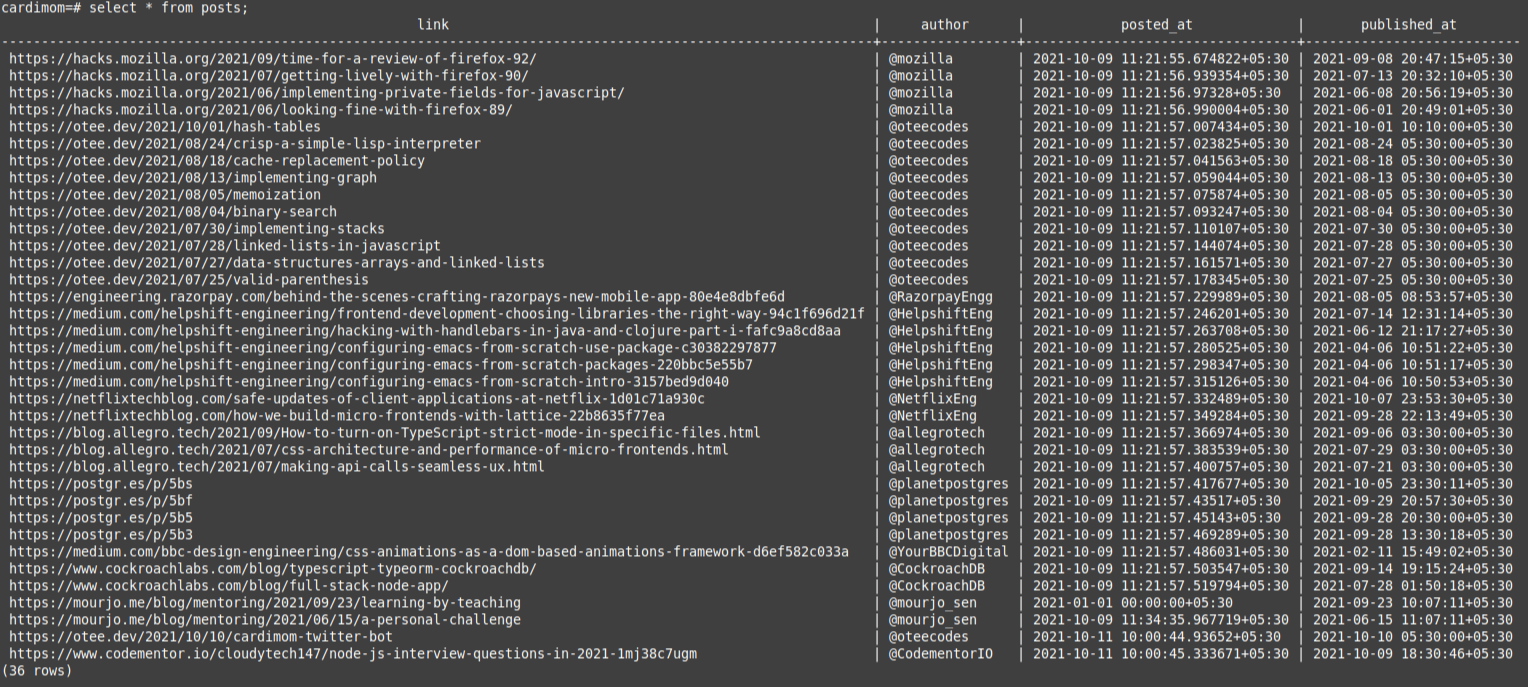
The above request would return a single timestamp:

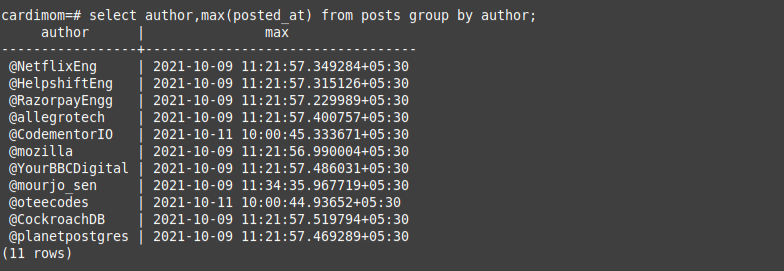
Now, the system makes a request for max timestamps of every author:
select author, max(post_at) from posts group by author;
This request returns a list of timestamps, grouped by each author:
Watermark as an alternative to cursors
Having a unit-level cursor is often not feasible for all applications. For example, while running Google Maps, it may not be possible to maintain one cursor for every mobile device.
Also, cursors cannot provide any guarantee towards recency, especially with respect to large-scale data analysis. If we need to publish time-sensitive data, we will have to ensure to receive sufficient amount of the data required for analysis. Let’s take the example of a hypothetical Twitter Bot that publishes only breaking news stories, once every hour. In this case, it would be crucial that only stories that are published recently get picked up by the system. Solely relying on cursors will not help, as the system will accumulate every story from every news website that was not seen earlier by the system. This could include, for example, a news story that was published days earlier which (for some reason) was not picked up during the previous system runs.
Thus, recency guarantee is not possible with cursors. Watermarks solve this problem, by maintaining a notion of running a lower bound on a given timeline, such that if a particular timestamp on that timeline is seen, we ignore events seen thereafter. In the above hypothetical example, imagine if the system waits for a specified period of time after each hourly period, and considers every news story it sees during that waiting period as breaking news for that hourly period. This ensures that only recent stories are published every hour, while also accounting for stories that may not have reached on time (i.e., out of order events). But, it also means that the system will potentially leave out some stories which fail to reach the system by this specified waiting period.
Watermarks can broadly be of two types: event-based and processing-based. For event-based watermarks, there is no notion of real time (wall-clock time as maintained by the processing system). Let’s take an example where the additional waiting period, or watermark, is set to 30 minutes. For a window of one hour beginning at 10:00, the system will wait till it sees an event bearing a timestamp greater than 11:30. The system will start processing all the events bearing timestamps between 10:00 and 11:00, only after it sees an event with a timestamp greater than 11:30. Note that, the system ignores when (on the wall-clock) the events bearing the watermark timestamp is actually seen. This can be significantly later than the 30-minute waiting period (for example, if the event source(s) remain unreachable for several hours). Event-based watermarks allow for prioritising accuracy over latency.
In processing-based watermarks, the cut-off time-period is determined as per the wall-clock of the processing system: the system will wait for a defined time-period before processing events belonging to a particular window. This is mainly useful when time is of the essence. For example, while live-tracking traffic data, where data processing is time-sensitive, we cannot afford to wait for an indefinite period for events bearing a particular watermark timestamp to arrive. Instead, the system will begin processing events for a given window, the moment the watermark timestamp is reached.
Watermarks provide an approximation approach where we choose to compromise on the overall accuracy (by not waiting for processing every single data for a given window), in the interest of processing a large amount data at a given latency. In the case of Cardimom, we do not need watermarks, as we are interested in 100% accuracy, and there is no handicap in having indefinite delays. We could, however, have used watermarks to only consider all unique posts published in the last 6 hours as well (similar to the breaking news example). A down side of this approach would be that the system would miss posts bearing older timestamps (that may have been skipped by the system in earlier system runs).