12 Things to Know About HTTP
This post all about HTTP and how the world wide web works.
1. What is HTTP?
HyperText Transfer Protocol (HTTP) is a network protocol that dictates how information is exchanged on the web. A network protocol refers to a system of rules and conventions that governs how two devices of a communication system (or network) exchange information. HTTP is a client-server protocol, meaning that it involves exchange of information between a client and a server.
2. What is a server?
A server is a computer or a system where the files and resources which make up a website, are actually stored. It connects to the internet and facilitates the exchange of data with other client devices connected to the web.
A server has a software component and a hardware component. The hardware component refers to the physical computer that stores the website’s software and files. The software component determines and controls how web users (i.e. clients) can use files hosted by the server. At a basic level, it refers to an HTTP server.
3. HTTP is State-Less
HTTP works by way of exchange of individual messages between clients and servers. However, each message is independent of each other: there is no link between successive requests or responses. Each message sent by a client should be self-contained and sufficient enough for the server to process it and send a response. This makes HTTP a state-less protocol.
4. What is a URL?
Uniform Resource Locator, or URL, is a web-address (often called a ‘link’) which points to a resource on the web. Plainly speaking, URLs are resource locations that a browser needs to know to retrieve a specific set of data. URLs are also the human access point to the web: by typing in the URL, the browser (or any other user agent) will initiate a set of steps to reach the resource location and retrieve information.
For example, the URL of this page is : https://otee.dev/2021/11/03/HTTP-explainer.html
Every URL must conform to a specific syntax. Accordingly, a URL typically consists of the following parts:
- Scheme: This is the first part of a URL. It indicates the protocol that the user agent (i.e., the application generating a request on behalf of the client) must use, to access the resource. In the above example, the scheme is HTTPS, which is an extension of HTTP providing a secured connection. The two most common protocols while accessing resources on the web, are HTTP and HTTPs. But there are other protocols as well, such as FTP and SMTP
- Domain: After the scheme, comes the domain, which indicates the web server from where the web resource is requested. Typically, a domain name is used, such as
otee.dev. But one can write the IP address of the web server as well. After the domain, the name of the port may also be mentioned, in the following manner:domainName.com:80. The domain name refers to the location of the physical web-server while the port refers to the exact location in the web-server where the web resource is actually hosted. The name of the port can be omitted from the URL, if the server uses the standard ports of the HTTP protocol (80 for HTTP and 443 for HTTPS). - Path: The path refers to the path to the specific web resource, on the web server. The path starts with a / :
/2021/11/03/HTTP-explainer.html - Parameters: After the path, the URL can contain certain parameters, that provide additional information to the web-server to help it process the client’s request appropriately. Parameters are separated from the rest of the URL with a
?and contain a list of name-value pairs. Here’s an example:http://example.com/news/search?type=breaking&limit=50. In this example, there are two pairs of parameters:type=breakingandlimit=50. These words have no special meaning in HTTP; it will carry the meaning as ascribed by the specific server.
5. How does a Client Connect to a Server?
To connect to a web server and exchange messages, an HTTP client needs to establish a connection (called ‘TCP’ connection) with the server. To establish this connection, the client needs to know the location of the web server, namely, its IP address and TCP port number. This information can be fetched from the URL.
The domain name of a URL is a human-readable alias for the IP address. The user agent converts a textual domain name to an IP address through a facility called the Domain Name System (DNS). The DNS, is like a phonebook: it maintains a map of domain names and their corresponding IP addresses.
Once the IP address of the web server is found, the user agent of the client initiates the ‘Transfer Control Protocol’ with the web server and starts sending and receiving HTTP messages to the web server.
6. What are HTTP Messages?
Clients and servers communicate with each other, over the web, by exchanging individual messages. Messages sent by a client are called HTTP requests and the messages sent by server to the client are called HTTP responses.
Request messages request an action on the web server (e.g. requesting access to a web resource) and response messages carry results of the request back to the client.
An HTTP message comprises of the following parts: a start line line, headers, and a body.
7. Start line
This is the first line of any HTTP message.
For HTTP requests, the start line is called a ‘request line’, and contains the following components: a method, the path component of the URL(along with parameters, if any), and the HTTP version (eg. HTTP2). The first line of the following image, shows the request line for this post.

Note that in the above example, GET is the name of the method, /2021/10/20/using-heroku-scheduler-to-initiate-triggers.html is the path component of the URL and HTTP/2 is the HTTP version followed by the server.
For HTTP responses, the start line is called ‘response line’, and it contains the HTTP version, and a status code.

In the above example, HTTP/2 is the HTTP version and 200 is the status code.
8. Headers
HTTP headers are used to convey certain additional information about the HTTP message. HTTP headers are a list of name-value pairs. There are certain standard headers which are often sent along with request and response messages. But we can send our own headers along with a message as well.
Here are examples of a few common headers:
user-agent: This is a request header, which identifies the user agent generating a request.
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/100.1 (KHTML, like Gecko) Chrome/1.0.0.81 Safari/100.36
content-type: This is a representation header which describes the actual media type of the body, prior to any encoding that may have taken place for sending it across the web. In case of response messages, this header informs the user-agent the type of the content (image, JSON object, html file etc.) that is returned by the server.
Content-Type: text/html; charset=UTF-8
Set-Cookie: This is a response header, which is sent along with a response message to instruct the user-agent of the client to store a list of cookies. Multiple cookies can be sent under this header. Each cookie is, in turn, a key-value pair, wherein, the key and the value are separated by=(nameOfCookie=Oreo).
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
Cookie: Once a cookie has been sent by the server, the user-agent is expected to send back those cookies in subsequent request messages using theCookieheader. In the case of theCookieheader, the entire list of cookies can be sent under one header and each pair is separated by a;(Cookie1=Swiss ; Cookie2=Vanilla).
cookie: yummy_cookie=choco; tasty_cookie=strawberry;
9. Body
HTTP message body (also called ‘entity body’) is an optional part of a HTTP message. It is the third and last part of an HTTP message and is separated from the headers with an empty line. The body of an HTTP message is the actual data that is transmitted during an HTTP transaction.
The body of an HTTP message can carry various types of data, including text, HTML documents, JSON, images etc. This makes the content headers (such as content-type) very crucial, as they describe the type and size of the content of the body.
10. Request Methods
Request methods, often called HTTP verbs, describe the nature of action that needs to be performed by the server on a resource. These are the four most common methods used in HTTP requests:
GET: This is the most common method and is used to ask the server to send a specific resource.POST: This method is used to submit a resource with the server (such as sending login credentials of a user), which often causes a change in the state of the server.POSTaims to write data onto the server, whileGETaims to merely read existing data from the server.PUT: This method is used to replace an existing representation on the server with a resource sent by the HTTP request.DELETE: This method is used for deleting a specified resource from the server.
Apart from the above four headers, there are other kinds of headers as well, such as: HEAD, CONNECT, OPTIONS, TRACE etc.
12. Status Codes
Just as methods tell the server what to do, status codes tell the client what happened with the request. Status codes are three-digit numeric codes, ranging between 100 and 599. Status codes often are accompanied by a short reason phrase, which summarises the meaning of that code.
Each code has a definite meaning and is maintained by the Internet Assigned Numbers Authority. They are classified into five categories, on the basis of the first digit:
1xx: Informational2xx: Success3xx: Redirection4xx: Client Error5xx: Server Error
Two of the most common status codes are: 200 and 404. 200 stands for OK, implying that the HTTP request was successful. 404 stands for not found, implying that the requested resource could not be found.
Not all the codes of each category have a definite meaning ascribed by the protocol. For example, the status code 580 does not have any specific meaning.
13. Making HTTP requests over CLI:
Apart from browsers, we can generate HTTP requests over the Command Line Interface (CLI) using, cURL, which stands for client URL. The simplest usage of this tool is to write the URL along with the keyword curl:
$ curl https://otee.dev/
The above command will return the body of the response message(in the above example, this would be an html file). curl assumes the request method to be GET, if we do not mention it. So, if we want to send a request with any other method, we should use the -X option followed by the name of that method:
$ curl -X POST http://localhost:4000/
Also, we can send specific headers (including customary ones) using the -H or -head option:
curl -H 'Content-Length: 13' http://localhost:4000/
curl supports over two hundred options, making it a versatile tool for generating API requests, checking for errors etc. Here are a few options that can come handy:
- Saving output: To save the body of the response message received, we can use the option
ofollowed by the location of the file where we want to save the output:
$ curl -o output.html https://otee.dev/
- Only headers: If we only want to see the headers of the response message (and not the body), we can use the option
-I
$ curl -X GET -I http://localhost:4000/
- Verbose: Sometimes it’s important to see everything that takes place under-the-hood, between typing-in a request and receiving a response. This can be done by using the
-vor--verboseoption. This is especially useful for debugging. In fact, whenever there is any error while generating acurlrequest, the “first instinct” should be to use this option. The verbose option makes curl “more talkative”
$ curl -v http://localhost:4000/
The above request returns the following response:
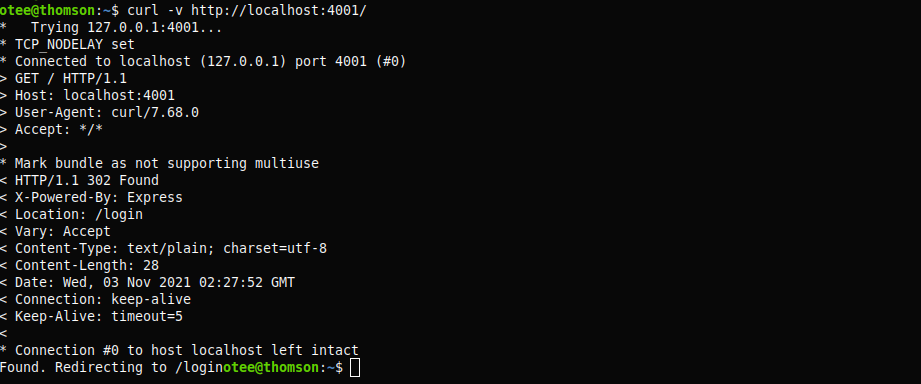
- In the above response, lines starting with
<indicate headers that were send along with the request message, the lines starting with>indicate the headers received along with the response message and the lines starting with*provide additional information. As the above example involved a simple server, the response received using this option was quite succint. But this is not the case with real-world websites. The response often runs to several lines. Also, the entire body of the response message gets listed at the end, making it difficult to read. So, to shorten the output, we can redirect the response body to a null device,/dev/null
$ curl https://otee.dev/ -v > /dev/null
- Follow redirects: Unlike browsers and other such user-agents,
curldoes not follow redirects automatically. So, in case a resource is shifted to another location, the server would send a response (with status codes301‘moved permanently’ or302‘moved temporarily’) specifying the new location, with the expectation that the client should head there to get their response. We need to use the option-Lor--locationto explicitly tell curl to follow redirects.
$ curl https://oitee.github.io/ -L
- Posting data: When using the POST request method, it is often necessary to send a body with containing relevant date. This can be done using
-dor--dataoption. We can send multiple name-value pairs using this:
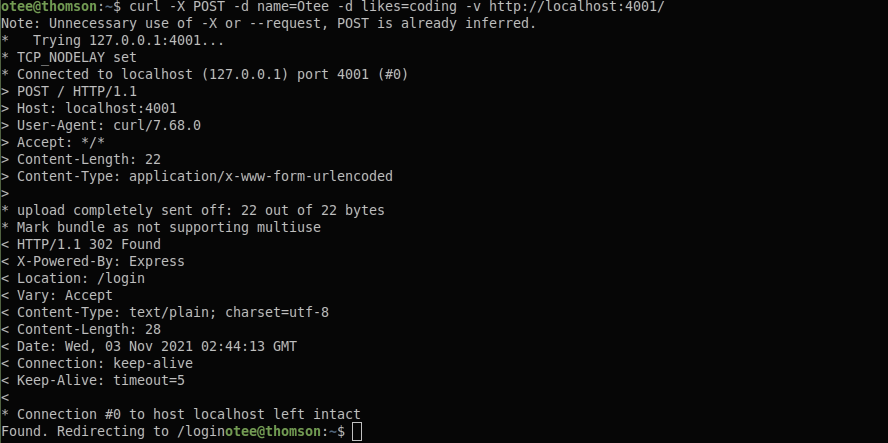
$ curl -X POST -d name=Otee -d likes=coding http://localhost:4000/
Why name-value pairs? The default content-type for POST requests is application/x-www-form-urlencoded. See the last request header of the example below:
So, in case, we want to send any other type of data, we should explicitly modify the content-type header accordingly: