Cardimom: Using Heroku Scheduler to Initiate Triggers
In this post, I discuss how I used an external scheduler to run the Cardimom application, in order to prevent usage of Heroku’s dynos unnecessarily.
The Problem
The Cardimom system is set to run once every hour, mainly to prevent exceeding Twitter’s rate limitations. This was achieved using the function setTimeInterval. This ensured that the launch function in the launcher module is invoked once every sixty minutes:
setInterval(launch, 60 * 60 * 1000);
However, as the trigger for each system run was managed by a function (setTimeInterval) inside the launcher module, the system was effectively running idly during the intervening period. Thus, to Heroku, where the application is deployed, the system was being run continuously, without any intervals. This meant that Heroku needed to allocate dynos for running the system, even when there was no post being fetched by the system. This resulted in an unnecessarily large number of dynos being used up by the Cardimom application. As a result, Heroku sent an email, notifying that 80% of the “550 free dyno hours” for the current month was already utilised.
Using a Scheduler to Initiate Triggers
Clearly, if we want to run the system on an hourly basis, there is no need for using Heroku’s dynos when the system is idle. To achieve this, we need to move away from relying on a trigger within the system and choose an external scheduler that can periodically trigger the system. This will ensure that we only use up Heroku’s dynos when the system is actually running.
This was achieved by using Heroku Scheduler. First, the setInterval function was removed. Thereafter, the Heroku Scheduler add-on was installed using the following command:
heroku addons:create scheduler:standard
The Scheduler dashboard was opened using the following command:
heroku addons:open scheduler
From the Scheduler dashboard, a new job was created that would ensure that the system is run once every hour. In other words, the Scheduler add-on will ensure that the following command is executed every hour:
## src/launcher.js is the location of the main file of the project
node src/launcher.js
Unforeseen roadblock
As discussed above, the goal is now to run the system at every interval, on the basis of external triggers. As a corollary to this, we need to ensure that the system is definitively exited during each run. To do this, we need to ensure that all asynchronous tasks are completed. To this end, we ensured to close the connection pool with the database, after the launch function has been called from the launcher module:
// 'db' refers to the module that connects to the database
await launch();
await db.poolEnd();
However, once we added the db.PoolEnd() command, an error was thrown:
Error: timeout exceeded when trying to connect
at Timeout._onTimeout (/home/ot/projects/newdir/node_modules/pg-pool/index.js:197:27)
at listOnTimeout (node:internal/timers:557:17)
at processTimers (node:internal/timers:500:7)
file:///home/ot/projects/newdir/src/post_db.js:52
let existingLinks = new Set(res.rows.map((row) => row.link));
^
TypeError: Cannot read property 'rows' of undefined
at Module.selectNewPosts (file:///home/ot/projects/newdir/src/post_db.js:52:35)
Upon investigation, it emerged that the problem lied in the following part of the launch function:
async function launch() {
// ...
db.selectNewPosts(listOfPosts)// .....(1)
.then(db.addNewPosts)
.then((newPosts) => twitter.publishTweets(twitterCredentials, newPosts));
//...
}
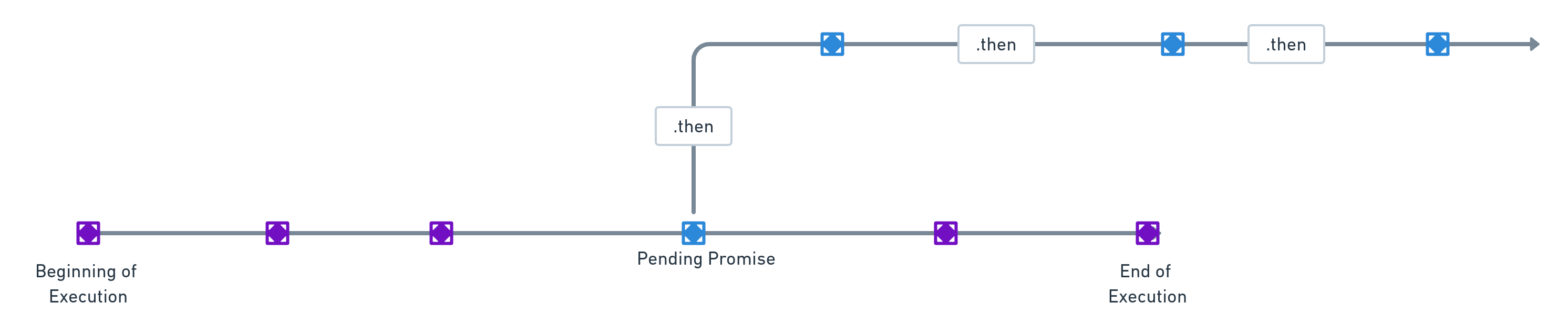
The promise created in the line marked as 1 above caused the error to be thrown. The function db.selectNewPosts is an asynchronous function. It returns a pending promise. Once this promise is resolved, the subsequent asynchronous functions, chained together by .then, are invoked and resolved.
Now, keeping in mind that the launch function invokes a set of asynchronous functions, the keyword await was originally used while invoking launch . It was expected that the compiler would proceed further, only after the promise returned by launch had been resolved.
However, note that neither await nor return was used while invoking db.selectNewPosts and its subsequent chain of asynchronous functions. This means that the promise returned by launch and the promise returned by db.selectNewPosts are distinct and different. Effectively, the compiler would not pause the execution of the rest of the launch function, till that promise returned in line 1 is duly resolved.
Thus, when launch is invoked (by using await), the compiler merely pauses till the promise generated by the rest of the launch function is resolved. As soon as this is done, it moves on to db.poolEnd to close the pool connection. This leads to a situation where the functions inside the db module (requiring access to the pool connection) lose their connection in the middle of their execution, thereby triggering an error.
To rectify this, the following changes were carried out:
async function launch() {
// ...
await db.selectNewPosts(listOfPosts)
.then(db.addNewPosts)
.then((newPosts) => twitter.publishTweets(twitterCredentials, newPosts));
//...
}
await launch();
await db.poolEnd();
Once we add await while invoking db.selectNewPosts , the compiler (while executing the launch function) will wait till all the promises linked to it are resolved. As a result, the db.poolEnd function will be invoked, only after, the requisite functions inside the database module have executed their tasks.
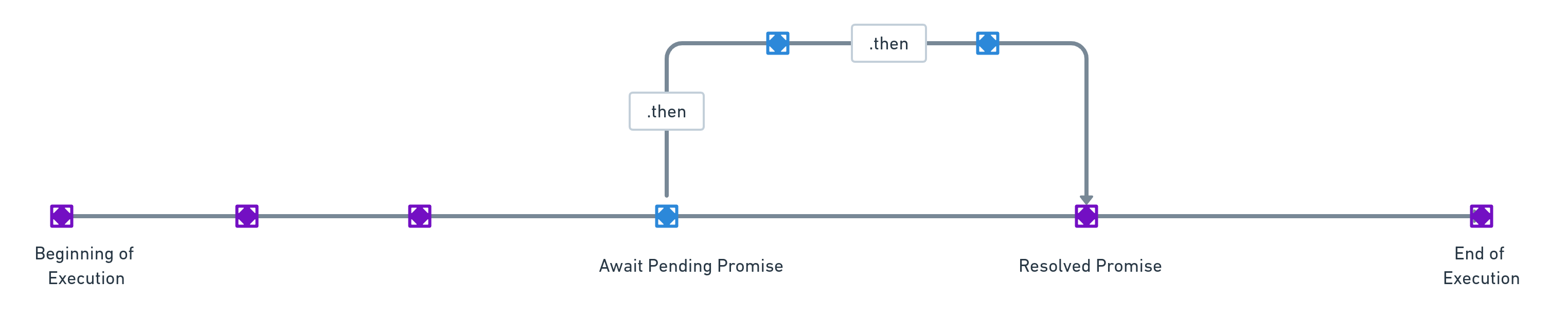
From the above problem, it is clear that when an asynchronous function is called, a pending promise is returned. Normally, the compiler will not wait for this promise to be resolved. In a way, the program will be executed in a parallel track: the compiler will proceed to execute the rest of the code, while the promises get resolved. This can lead to unexpected results: asynchronous tasks may be left pending while the rest of the program is finished in its execution.
Conclusion
From the above discussion, it emerges that when it comes to applications such as Cardimom, which are run after periodic intervals, it is computationally more efficient to rely on an external scheduler to trigger the system periodically, instead of relying on the system itself to carry out periodic runs.