Short, Unique, & Unguessable: Generating Short Links in Twirl
This is the third and final part of a three-part series on Twirl—a web app that shortens URLs on a per-user basis. Twirl is deployed on Heroku and can be accessed here: https://oteetwirl.herokuapp.com/
In the first part, I gave an overview of the project structure of Twirl and discussed the user management component of the application. In the second part, I made a deep-dive into how passwords should be stored in databases and showed how we store passwords in Twirl.
In this part, I discuss the link shortening logic used in Twirl.
Design Goals
Twirl has three design goals for generating short links. First, links should be short. This is obvious: the primary goal of the application is to generate short links.
Second, the short links generated by the system should be unique. In other words, no two short links should be identical to each other. Uniqueness of short links ensures that we have a one-to-one mapping of short links to long (or original) links. If the system produces the same short link for two or more URLs, this will lead to ambiguity and uncertainty: a given short link would redirect to one of many alternative long links.
Third, short links should be unguessable. In other words, the system should generate short links that appear random, making it nearly impossible for an external observer to predict the links generated by the system. This ensures that no third-party can predict future (or past) links generated by the system and alter their access count.
Also, Twirl guarantees that multiple requests for shortening the same URL will result in the same short link, if these requests are made by the same user. However, if the same URL is shortened by different users, they will receive unique (and different) short links. This, again, helps in keeping a tab on the number of times a particular link generated by a specific user has been accessed.
Generating Short links
To generate short links, the system creates a unique string (e.g. 4i811) and appends it to a specific path, namely /l/. Thus, each short link comprises the following parts: {domain}/l/{unique_string}.
To ensure that the aforementioned design goals are realised, we need to make sure that this unique string meets the triple requirements of being short, unique and unguessable.
The unique string (forming the path of each short link) comprises two parts. To ensure that the string is unguessable, the first part is a pseudo-random string, which is generated using the randomBytes method of the crypto module of Node.js. This method generates “cryptographically strong pseudorandom data”. It takes a size parameter—indicating the number of bytes of pseudorandom data to generate—and returns a Buffer object representing the pseudorandom data. Buffers are designed to handle and represent raw binary data in Node.js.
To read the contents of the buffer object, we can use the in-built toString method to convert it into string data-type. By default, toString uses the UTF-8 binary-to-text encoding scheme. This is undesirable, as the resultant string can contain any number of special characters that are not supported in a URL. (The UTF-8 scheme can encode as many as 1,112,064 characters while a valid URL should only contain alphanumeric characters along with a handful of reserved and unreserved characters).
Instead of relying on UTF-8, we use Base64 encoding to convert the Buffer object returned by the randomBytes method. Base64 encodes alpha-numeric characters (A - Z, a-z, 0-9) along with a few other special characters (such as +, -, / and =, depending on the specific implementation of Base64). So, to comply with the standards of a valid URL, we need to remove these special characters.
Also, to keep the resultant link short, we keep the size of this pseudo-random data to a minimum: we pass 2 as a parameter to the randomBytes method, ensuring that the size of the pseudo-random data is only 2 bytes.
import { randomBytes } from "crypto";
let shortLink = randomBytes(2).toString("base64");
shortLink = shortLink.replace(/[\-+\/=]/g, "");
To ensure that each short link is unique, we rely on counters. Note that randomBytes generates pseudo-random data; it does not guarantee any uniqueness but merely serves to obfuscate the resultant short link. To put it in another way, there is no guarantee that there will be no duplication in the data generated by randomBytes. Thus, to ensure that each short link is unique, the pseudo-random string is appended by a counter.
As the state of the system is maintained by the database, we store the current value of the counter in a specific table (namely, counters) in the database. The value of the counter is incremented by one, each time a short link is generated.
Need for atomicity while generating counters
If multiple servers access the same database and attempt to modify the same data, it can lead to duplication or inconsistency of the data being modified. In the present context, consider that the system processes each request for generating a short link by making two separate queries with the database: first, to update the counter in the database, and then, to read the value of the counter so updated. Now, if two concurrent requests are received (assuming the server can handle multiple threads), the server will make two sets of these queries, simultaneously. Ideally, the update-and-read transactions should happen sequentially, once for each request. But because the requests are being processed parallely, the two update queries (one for each of the two requests) may get processed first, before the two read queries. This will result in two short links relying on the same counter.
Let’s take an example. Let the present value of the counter (c) be 1. R1(c) indicates that thread 1 reads the value of the counter c. W1(c, c + 1) indicates that thread 1 writes the value of the counter by incrementing it by one. Now, this is the single threaded execution sequence:
W1(c, c + 1); // value of c is increased to 2
X = R1(c); // value of X is 1
Expected two-threaded execution sequence (with initial value of c as 1):
W1(c, c + 1); // value of c is incrased to 2
X = R1(c); // value of X is 2
W2(c, c + 1); // value of c is increased to 3
Y = R2(c); // value of Y is 3
However, because multiple threads run parallely, the following can also happen:
W1(c, c + 1); // value of c is incrased to 2
W2(c, c + 1); // value of c is incrased to 3
X = R1(c);
Y = R2(c); //the values of both X and Y are 3
This will reduce the uniqueness guarantee of the system. If the system receives multiple concurrent requests, it will be (at least) theoretically possible that two short links (generated for two different URLs) are identical, as they may rely on the same value of the counter and the same pseudo-random data.
To avoid this and to guarantee uniqueness of short links at all times, we use atomic transactions to update and read the counter values from the database. An atomic transaction is an “indivisible and irreducible series of database operations such that either all occurs, or nothing occurs”. The above example (involving two threads), breaks down because between the time you update the value and the time you read its value, the value itself gets changed (by another transaction). This can be avoided if we use atomic transactions: it ensures that the reading and writing operations are indivisible and thereby ensuring that we read what we write.
Atomicity can be achieved if we use the RETURNING clause in the query for updating the value of the counter. The RETURNING clause allows us to “obtain data from modified rows while they are being manipulated”. In other words, it rolls a SELECT operation into a query for modifying the database. This ensures that either both the updation and reading operation on the database will fail or succeed and that we will read the data being updated by each transaction.
UPDATE counters SET value=value+1 WHERE id='link_counter' RETURNING value
Finally, if a request for a shortening a link is made, the system first checks if the link exists in the database for the same user. If yes, it fetches the corresponding short link from the database, instead of generating a new short link.
Database Schema
There are two tables in the database, related to the shortening of links. First, the counters table, which maintains the counter, based on which short links are generated (as mentioned above).
Table "public.counters"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | text | | not null |
value | integer | | |
Indexes:
"counters_pkey" PRIMARY KEY, btree (id)
Second, a table, mamed links, which maintains the list of all the short links generated by the system. This table contains the following columns:
user_id: This is a foreign key, which references the id of the user (from theuserstable) which generated each short linkoriginal_link: Stores the corresponding original (long) link of each short link generated by the usershort_link: Stores each short link generated by the systemenabled: Maintains whether each short link is enabled or disabledaccessed_count: Stores the number of requests for expanding each short linkcreated_at: Stores the timestamp when each short link is createdupdated_at: Stores the timestamp when each short link is updated (currently, the system does not support any feature for updating links)
This table is dependent on the users table, as the user_id column of this table has a foreign key constraint on the users table.
Table "public.links"
Column | Type | Collation | Nullable | Default
----------------+--------------------------+-----------+----------+---------
user_id | uuid | | not null |
original_link | text | | not null |
short_link | text | | not null |
enabled | boolean | | not null | true
accessed_count | integer | | | 0
created_at | timestamp with time zone | | |
updated_at | timestamp with time zone | | |
Indexes:
"links_pkey" PRIMARY KEY, btree (user_id, original_link)
Foreign-key constraints:
"links_user_id_fkey" FOREIGN KEY (user_id) REFERENCES users(id)
Expanding short links
When a request is made for a short link generated by the system, the system will fetch the corresponding long link from the database. If the short link does not exist in the database, an error message is displayed. Note that, for fetching the corresponding long link of a given short link, the system does not check if the user (making the request) is logged in or not.
Other features
The links table keeps a track of the number of times each long link has been fetched from the database. This allows the application to display the top 50 short links (in terms of access count) of every user. Using the setInterval method, the front-end JavaScript periodically makes a request to the /analytics path. Each time a request for this path is received, the system fetches the top fifty short links of that user using the following query:
await pool.query(
`SELECT original_link, short_link, accessed_count, enabled FROM links
WHERE user_id=$1
ORDER BY accessed_count DESC, created_at DESC limit 50;`,
[userID]
);
The system also allows the user to enable or disable short links. When the user makes a request to the /disable/:id path, where id is the unique string of a short link, the system changes the value of the enabled column of the links table for that short link from true to false. Conversely, it changes the corresponding value of the enabled column from false to true when a request is made to the /enable/:id path.
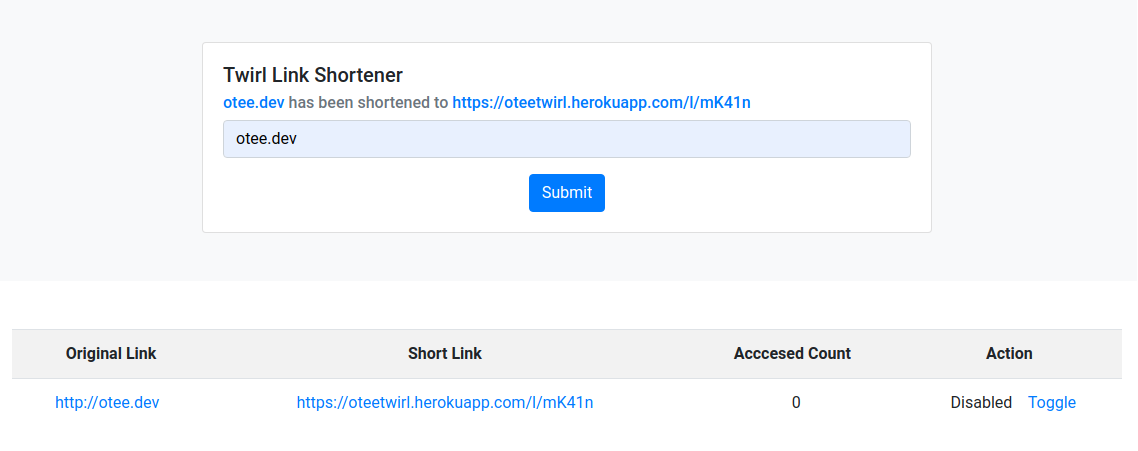
The front-end JavaScript generates the disabling/enabling requests, when the user clicks on the toggle button for a given link.
Future Improvements
Here are some of the improvements that can be introduced with respect to the link shortening part of the system:
- Alias: Allowing users to customize their short links by using custom aliases.
- Pagination: Adding pagination to display all the links generated by a user, instead of displaying only the top 50 links
- Adding searchability : Allowing users to search the links shortened by them.
- 404 Page: Adding a 404 page for links that are disabled by the user
- Caching: Enabling caching of a limited number of short links, by keeping them in memory
- Performance improvement: To reduce the number of queries made to the database for processing each link shortening request, the system can increment the unique counter (maintained by the database) by n values, thereby allowing it to create n short links without querying the database.
- Providing an API interface: Allowing third-party apps to use this app’s service; currently, requests for shortening of links need to be made by the browser, after a user signs in (as we look at the cookie headers to authenticate the user).