Twirl: User Management
This post is the first part of a three-part series on Twirl—a web app that shortens URLs on a per-user basis. Twirl is deployed on Heroku and can be accessed here: https://oteetwirl.herokuapp.com/
The design of this project can be divided into two key parts: user management and link shortening. The first part deals with the user sign-up and sign-in flow. It ensures that only users with valid credentials can access authenticated routes. The latter involves the business logic of shortening URLs, retrieval of previously shortened URLs and displaying analytics regarding each shortened URL of users. This post disscuses the first part of the project, namely user-management. The next post will discuss the latter part dealing with the shortening and expansion of links.
Scope
Twirl is a web app that shortens URLs. It allows users to sign up (verified with reCAPTCHA) and sign-in on the app and create short links by entering their original links. The app ensures protection of passwords by storing them in the database using salted hashing, by using the standard pbkdf2 function (imported from NodeJs’ Crypto library). Each short link is uniquely generated.
The app provides for two user-roles: admin and ordinary. Ordinary users can view the list of top 50 links shortened by them, the number of times each such short link has been accessed and an option to enable or disable them. Admin users can access the top 50 short links created by the app; however, an admin user is not given the permission to disable or enable links created by other users.
Project Structure
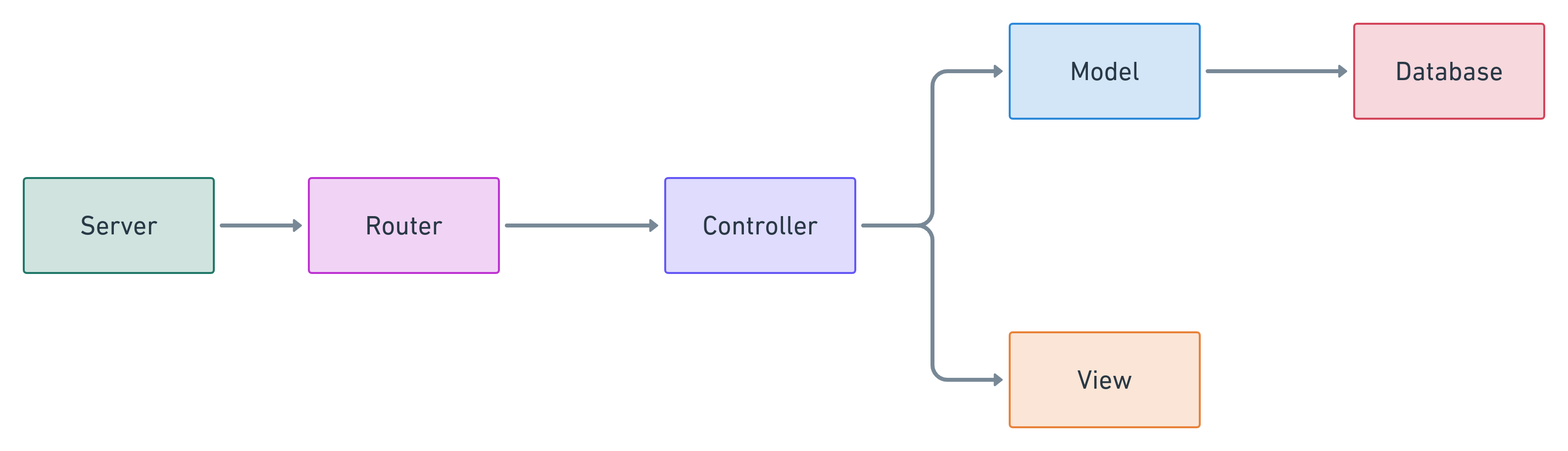
Model-View-Controller (MVC)
The project implements an Model-View-Controller architecture.
Model-View-Controller (MVC) is an architecture pattern which ensures separation of concerns between its components. It comprises of the following three components:
- Model: It maintains the state of the application. It interacts with the database, attends to requests for information from the database and changes the state of the database on the basis of instructions received from the controller.
- View: It is responsible for handling the user-interface of the application. It is in charge of displaying the output to the user.
- Controller: It interprets user inputs, commands the model to provide information or alter its state and instructs the view to display the output accordingly. It generally hosts the business logic related to the functionality of the application.
The model component and the controller component contain two separate modules: one each for handling the user management logic and the link shortening logic. The view component is shared by both.
User Management
Router-Server Separation
The handling of routes has been separated from the setting up of the server. The server module is responsible for setting up the server, initializing middlewares, setting up the template engine and starting the database connection.
The router module maps each URL request to the corresponding handler function in the controller. The handler function interprets the request message, reads the parameters or queries (if any) and accordingly interacts with the relevant function in the model. Finally, the controller interacts with the view component to display requisite output to the user.
Template Rendering Engine
The application uses the Mustache template engine. A template engine renders a template file and converts it into an HTML file, after replacing variables (on the template file) with certain values. This enables using a template file (which is otherwise static, like a HTML file) to generate dynamic content.
To use a template engine in Express, an application setting property–names that can be used to configure the behavior of the application (similar to environment variables in NodeJs)–called views needs to be configured with the location of the directory hosting the template files. Setting of application properties can be done using app.set:
app.set("views", __dirname + "/../public/views");
To use the Mustache template engine, the engine method of the Express application needs to be invoked and the extension of the template file and name of the template engine needs to be passed as arguments (the extension for Mustache templates is .mustache):
app.engine("mustache", mustacheExpress());
Cookies
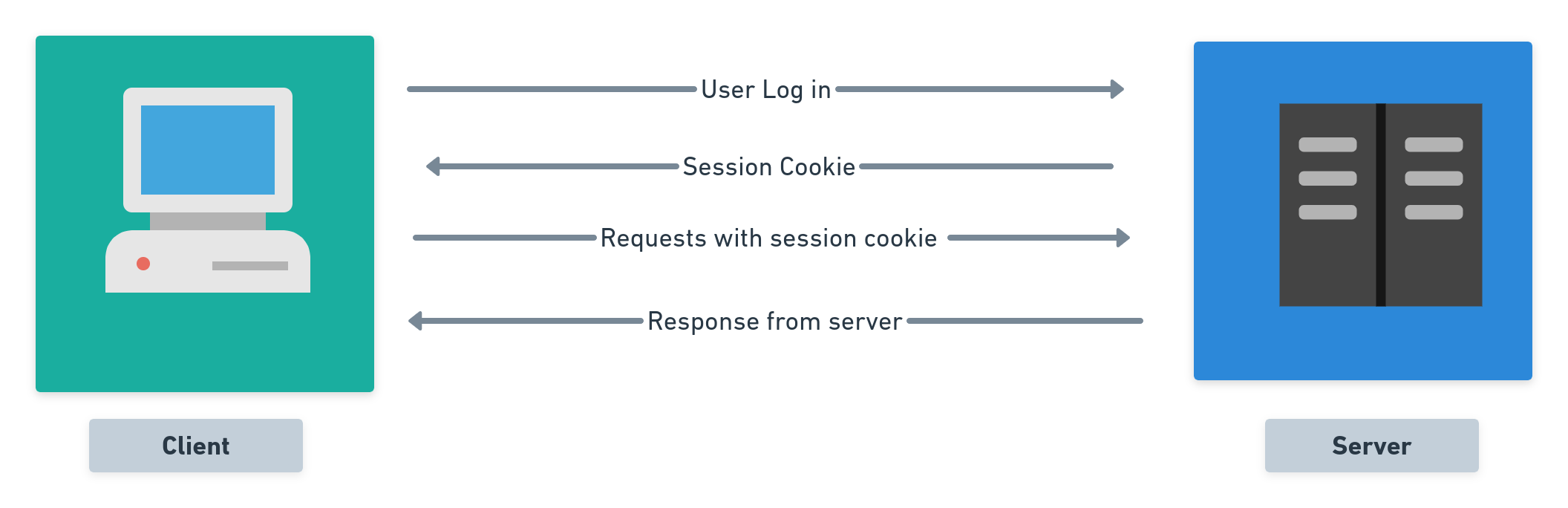
HTTP is a stateless protocol. This means that the server and the client rely only on individual messages to transact with each other. This makes it difficult to store useful information about a user, such as whether a user is logged in or whether two requests originated from the same client etc. HTTP cookies help in solving this gap.
A HTTP cookie is a small piece of data sent by a web server to a client’s user agent (i.e., a browser). The client stores this data and sends it back to the server along with every subsequent message. This helps the server to identify the client and maintain useful information about them.
HTTP cookies are used for three broad categories: session management, personalisation and tracking. In the present project, cookies are used to maintain information about user-sessions: cookies help the server understand whether a request is sent by a user who is already signed in. This validation is of great significance, as only users who are signed in to the system, are allowed access to the services of the app.
Once a user logs in, the server sends a Set-Cookie header, containing the name of the cookie, _twirl and the user_id of the user, as retrieved from the database. As this cookie will enable the server to verify the existence of a user-session, its called a session cookie. The Cookie header of every request message sent by the client will contain the cookie(s) sent by the server. Once the user logs out, the server instructs the client to delete the session cookie, by sending a new session cookie with an expiration time-stamp from the past, namely 01 Jan 1970 00:00:00 GMT.
Parsing and Writing Cookies in Express:
Express provides a middleware called cookie-parser, that parses the cookies from the Cookie header of a request message. Once cookie-parser is imported as a middleware, it creates a new property in the request object called cookies and maps it to an object containing the list of cookies (as a name-value pairs) sent by the request object.
To send a new cookie in Express (under the Set-Cookie header of a response object), the cookie method of the response object (in Express) needs to be invoked. This method accepts the name and the value of the cookie as its first two parameters. Optional parameters include, setting an expiration timestamp of the cookie (expires), an expiration time-period for the cookie (maxAge), preventing client-side JavaScript from accessing the cookie (httpOnly), ensuring that the cookie is sent over HTTPS only (secure) etc.
To ensure security, the project uses the httpOnly, and secure parameters while sending cookies to the client.
Need for Signed Cookies
Session cookies play a crucial role: they act as unique identifiers of users and are used by the server to give access to routes that require the user to be logged in (called authenticated routes). But cookies are stored by the client and can be manipulated by any user. This is why it is important to ensure integrity of the session cookie received by the server. This can be achieved by using ‘signed cookies’. Digital signatures ensure that the payload was not modified because only the server could have generated the signature of a specific payload. But still this does not guarantee that the user will not be able to read the cookie payload. So in order to do that, we obfuscate the cookie payload by encrypting the signed payload.
Middlewares
Authentication Middleware
As per the scope of the project, only logged in users should be able to access the application. This means that only if users can be authenticated, can they be allowed access to the home page, and generate requests to shorten links. Since this filtering needs to be done for almost all routes, a middleware called auth has been built that: a) checks if a route requires authentication for gaining access and, b) if so, it redirects to the login if the request object does not contain requisite session cookies.
There are two routes in the user-management part of the project, which do not require authentication (i.e., presence of session cookies) for access: the sign-up and login routes. Additionally, any routes requesting for expansion of a shortened link, do not require authentication (as anyone with a shortened link should be able to access the resource the corresponding original link points to). If a request is made for any of these routes, the authenticator middleware does not check for session cookies and allows the request to be handled by the appropriate route handler.
In the case of the two routes in the user-management part that does not require authentication, namely /login and /signup, the respective route handlers (for both POST and GET methods) first check for the presence of session cookies. If they are found, they send a response instructing the client to redirect to the home page. This ensures that anyone who is already signed in should not have to login or sign-up again. The only way to switch sessions is to first logout and then login or sign-up.
Redirecting HTTP Requests
The application redirects any requests sent over vanilla HTTP to the HTTPS counterpart. This is done by a middleware (called redirectIfNotHTTPS), which reads the x-forwarded-proto header inserted by Heroku. x-forwarded-proto is a part of a field of headers which are often inserted by proxies (such as Heroku’s router) to retain “the original information at the HTTP level” of the client who made the request.
Third-Party Middlewares
In addition to the above two middlewares, the app uses the following third-party middlewares:
urlencoded: Parses requests with urlencoded payloads (such as form data) and stores the parsed data as a new object in thebodyproperty of the request objectjson: Just likeurlencoded, this middleware parses requests with JSON payloads and stores them in thebodyproperty of the request object.cookieParser: Parses thecookieheader of the request object and populates their value as name-value pairs under a newcookiesproperty of the request object.cookieEncryptor: Encrypts and decrypts cookies.
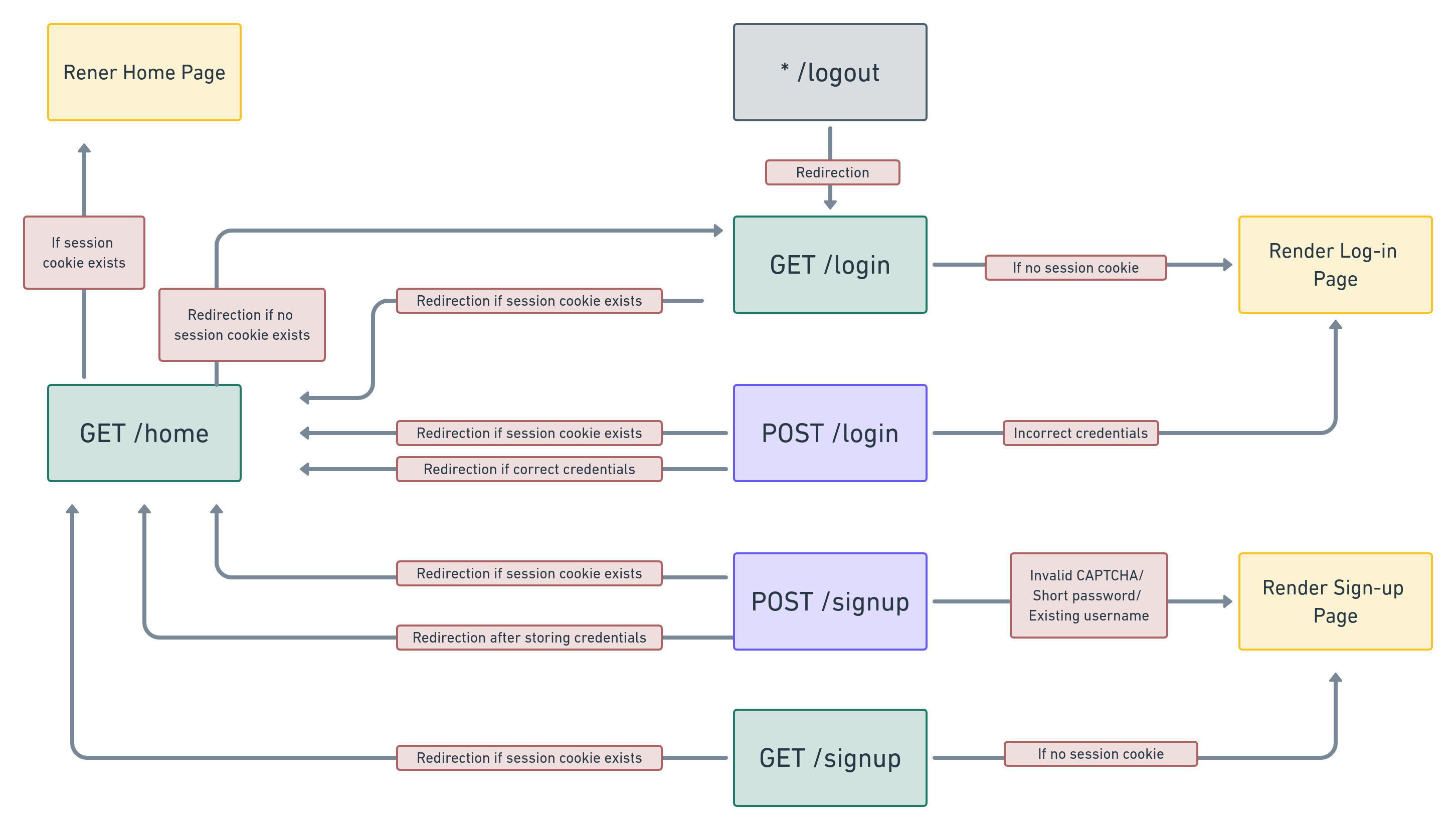
User Flow
The following routes form part of the user interface:
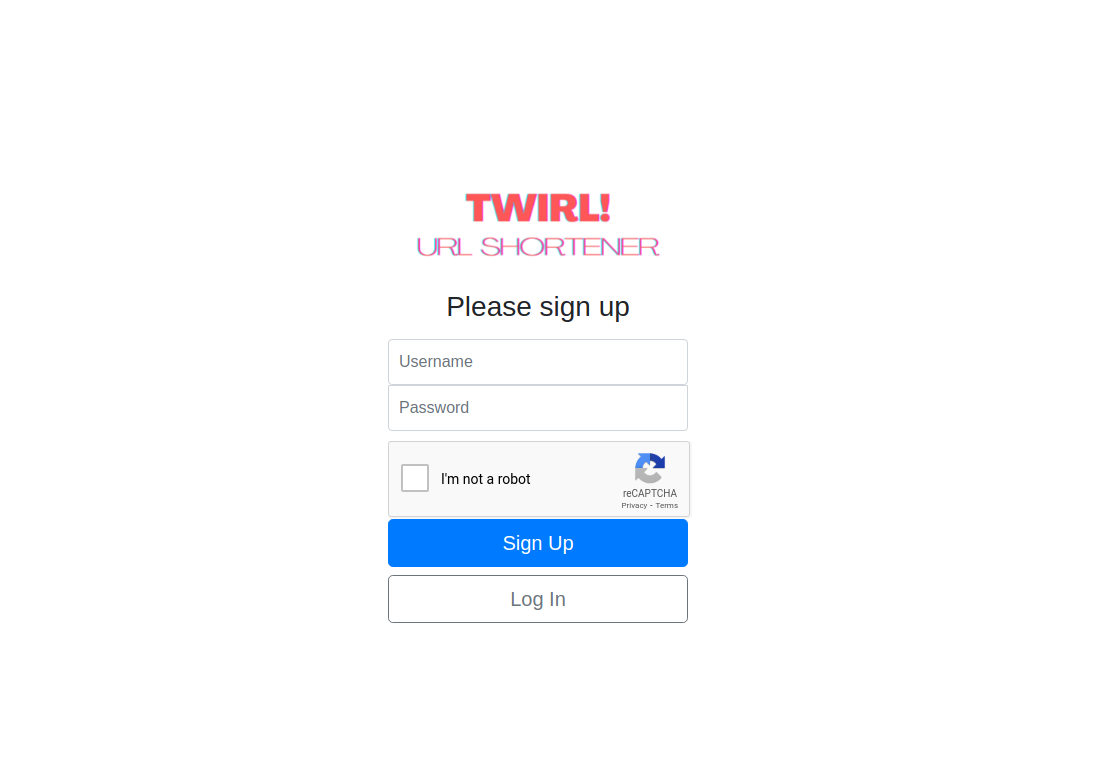
/signup: A request withGETmethod, renders the sign-up page. A request withPOSTmethod, results in storage of the username and password of the user, followed by a response message requiring the client to redirect to the home page. This is done by using theredirectmethod of the response object in Express. However, if the entered password contains less than 6 characters or if the username already exists, the signup process fails and the sign-up page is rendered again with an appropriate message to indicate the error in sign-up. reCAPTCHA is used during sign up to prevent bots from signing up
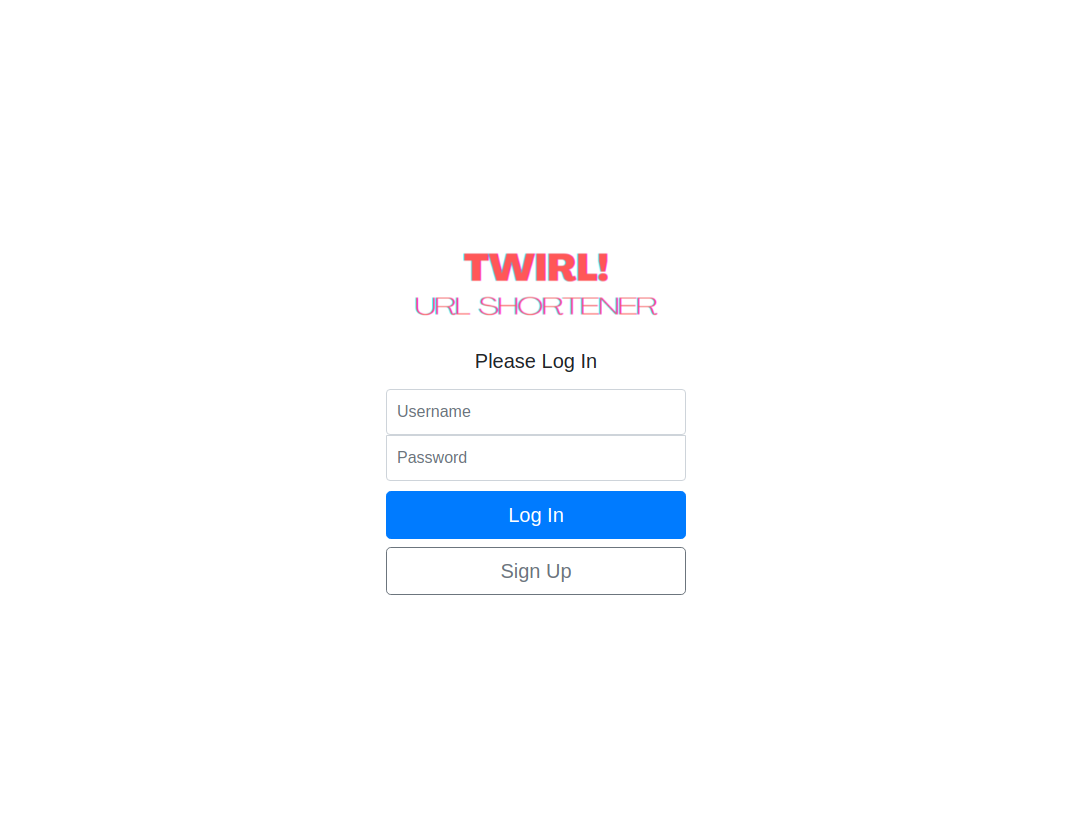
/login: A request withGETmethod, renders the login page. A request withPOSTmethod, results in verification of the entered password and username with theuserstable in the database. If the credentials are correct, the response message requires the client to redirect to the home page. Otherwise, the login page is rendered again, with a message indicating incorrect credentials.
/logout: A request with any method, results in a response message instructing the client to clear session-cookies and to redirect to the login page./home: A request withGETmethod, renders the home page. This is, like all other authenticated routes, subject to the authentication middleware not instructing the client to redirect to the login page, in the event of absence of session cookies.
Here’s a snapshot of the user sign-up and sign-in flow:
Database Schema
The application remains connected with a database, using PostgreSQL, which maintains the state of the application. This database, called twirl, contains the following tables:
users: For maintaining information about each userroles: For maintaining information about each user rolecounters: For maintaining a counter for each short link generated by the systemlinks: For storing each short link generated by the system
The tables users and roles are relevant to the user management part of the application. The subsequent post on link shortening, will focus on the other two tables, namely, counters and links.
roles Table:
This table maintains the different user-roles supported by the application, namely, normal and admin. For a normal user, the home page will display only the short-links generated by them; whereas admin users have the privilege to see the top links shortened by any user. Thus, while adding a new user to the system, it is important to maintain the user-role ascribed to them.
By design, the application only allows users to sign-up as normal users. It does not support a request to change user-roles. Given that admin users are expected to be few in number and in charge of overseeing the working of the system, users can be given admin access only by manually modifying the roles table, by writing a query on PostgreSQL.
The roles table contains the following columns:
id: To store the unique id of each rolename: To store the name of each role
Here’s the schema of this table:
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+-----------------------------------
id | integer | | not null | nextval('roles_id_seq'::regclass)
name | text | | |
Indexes:
"roles_pkey" PRIMARY KEY, btree (id)
Referenced by:
TABLE "users" CONSTRAINT "users_role_id_fkey" FOREIGN KEY (role_id) REFERENCES roles(id)
users Table
This table maintains all the relevant details of each user who has signed up on the system. This table is accessed while authenticating a sign-in and for storing new users during a sign-up. It contains the following columns:
id: To store the unique id of each userusername: To store the username (as entered by each user during sign-up) of each userpassword: To store the password of each usercreated_at: To store the timestamp when a new user was added to the systemrole_id: To store the id of the role (from therolestable) of each user.
This table is dependent on the roles table, as the role_id column has a foreign key constraint. A foreign key constraint ‘maintains referential integrity’ between two related tables. In other words, the values in one column must match the values of a specific column of another table. To add a foreign key the REFERENCES keyword should be used:
CREATE TABLE users (
...
role_id INTEGER REFERENCES roles (id)
);
In the case of the users table, the column role_id has a foreign key constraint, such that its values must match any of the values stored in the id column of the roles table. This means that Postgres will reject insertion of any values in the roles_id column of users which do not appear on the id column of the roles table. Placing a foreign key constraint on the roles_id column prevents the system from accepting new users whose roles are not already defined in the roles table.
The id column of the users table is meant to store unique identifiers of each user. This will be used by the links table as a foreign key constraint to keep a track of users and their respective short links. As the values in the id column need to be unique, it has uuid data-type. UUID, which stands for ‘Universally Unique Identifiers’, is a unique identifier generated by an algorithm which can guarantee a near-zero probability of duplication.
Instead of storing the raw password in the password column, the salted hash of the raw password is stored so that in case the table is exposed, the original passwords cannot be guessed from it.
Here’s the schema of the users table:
Column | Type | Collation | Nullable | Default
------------+--------------------------+-----------+----------+---------
id | uuid | | not null |
username | text | | not null |
password | text | | not null |
created_at | timestamp with time zone | | |
role_id | integer | | |
Indexes:
"users_pkey" PRIMARY KEY, btree (id)
"users_username_key" UNIQUE CONSTRAINT, btree (username)
Foreign-key constraints:
"users_role_id_fkey" FOREIGN KEY (role_id) REFERENCES roles(id)
Referenced by:
TABLE "links" CONSTRAINT "links_user_id_fkey" FOREIGN KEY (user_id) REFERENCES users(id)
Future Improvements
Here are some of the improvements that can be introduced to the user management part of the project, in the future:
- Log-in using Google: Instead of storing the username and password of every user in the app’s database, the app can allow users to log-in and sign-up by using their credentials with Google. This can enhance the security of the system and increase the ease of access of the end-user.
- Remember-me feature: When a user logs in or signs up with the app, a session cookie is sent to the client, which is used for authenticating the client for subsequent requests. However, session cookies get cleared at the end of each session, i.e., when the user logs out or closes the browser. The app does not provide an option to the user to stay logged in between sessions. Thus, as a point of further improvements, the app can provide users with an option to remain logged in with the app between sessions.
- Change password: The app currently does not allow a user to modify an existing password. This may be allowed as an additional feature.
- Forgot password: The app does not allow users to reset their passwords, if they forget their existing passwords. This may be enabled as a future improvement, by letting users to type-in previous passwords or by mailing users unique links to reset their passwords.
In the next part of this series, I discuss how passwords are stored in Twirl. In the final part, I discuss the how short links are generated by Twirl.