Ping-pong: Using multiple Kafka consumers to process events
In this post, I write about ping-pong - a project that aims at simulating how messages in a live chatroom (with multiple concurrent users) may get processed, using a Kafka messaging system.
This project makes use of a Kafka producer to push user messages to a topic and uses two independent Kafka consumers to process them. Here’s the github repository for this project: https://github.com/oitee/ping-pong
- System Components
- Demo
- Generating user-messages
- Processing User Messages
- Importance of passing event timestamp
System Components
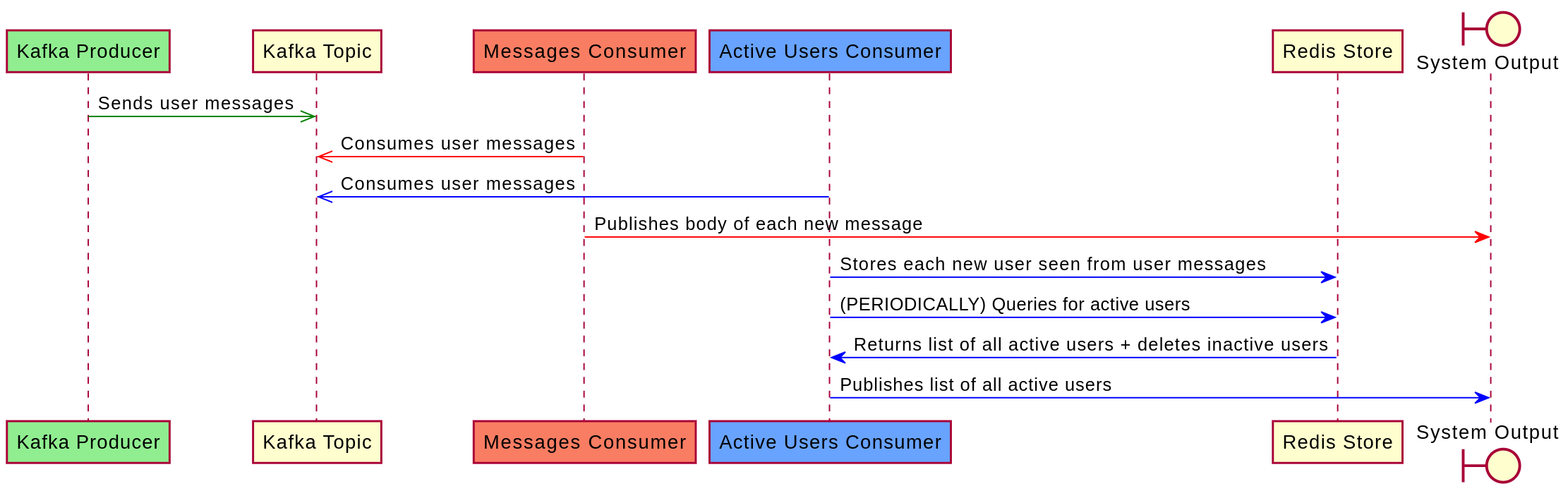
Largely, the system relies on a Kafka producer to push each new user message and on two independent Kafka consumers to process each new message:
- Kafka producer: It pushes new user-generated messages to a common Kafka topic. These messages are meant to be consumed by different consumers.
- Messages consumer: This consumer reads each event (containing user-generated messages) from the Kafka topic and prints out the contents of each user message
- Active users consumer: This consumer consumes each Kafka event and periodically publishes a list of all active users.
- Redis: The active users consumer stores each active user, in a Redis store, and periodically fetches the list of all active users from this store.
The interaction of the above components are demonstrated in the following sequence diagram:
Demo
Before going ahead with further details, here is a demo of the system:
Generating user-messages
User-messages have to be generated before pushing them to the Kafka producer. To simulate a chat-room:
- A list of users is hard-coded in the project (present in
ping-pong.utilsname-space). As an avid fan of The Office (US), the users are all the characters of The Office(US) -
Using the list of user-names, a one-time list of emails for each user is generated by randomly using a list of common email domains and the user-names of each user. Each user entity, thus, is represented as follows:
{:user "Micheal Scott" :email "micheal.scott@gmail.com"} - The list of user-entities is stored in an atom called
usersin theping-pong.usersnamespace. This namespace exposes a function calledget-userthat randomly returns a user-object from this atom. - The
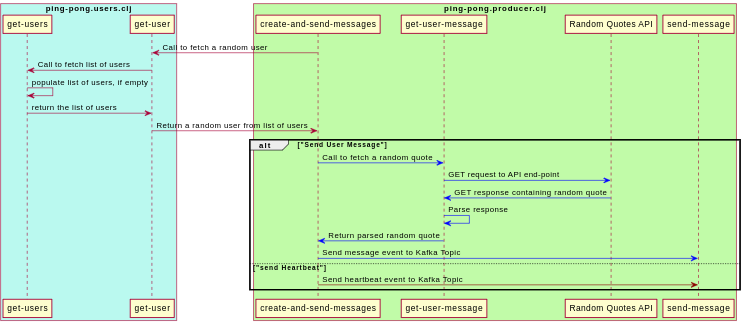
ping-pong.producerperiodically fetches a user-entity from this function and sends two types of Kafka events:-
Messages: Every second, after fetching a user entity, it makes a HTTP get request to an open API which returns random quotes. This forms the message body of the respective user. Finally, it sends the Kafka event. Here’s a snapshot of how this is done (the entire namespace can be found here):
(def quotes-url "https://favqs.com/api/qotd") (defn get-user-message [] (let [response (clj-http.client/get quotes-url)] (if (= (:status response) 200) (-> response :body cheshire.core/parse-string clojure.walk/keywordize-keys (get-in [:quote :body])) ""))) (defn create-and-send-messages [interval] (while @continue? (let [current-ts (System/currentTimeMillis) {:keys [name email]} (ping-pong.users/get-user) user-message (get-user-message) activity (:send-message ping-pong.utils/allowed-activities)] (send-message (cheshire.core/generate-string {:user name :email email :activity activity :message user-message :ts current-ts}))) (Thread/sleep interval))) -
Hearbeats: These events are sent at random intervals (between 1 and 7 seconds) and are meant to represent a user is active, even though they are not typing a new message. Unlike a message event, a heartbeat event does not contain any
messagekey in the payload(the entire namespace can be found here):
(defn send-heartbeats [] (while @continue? (let [current-ts (System/currentTimeMillis) {:keys [name email]} (ping-pong.users/get-user) min-interval 1000 rand-interval (+ min-interval (rand-int 7000)) activity (:heart-beat ping-pong.utils/allowed-activities)] (send-message (cheshire.core/generate-string {:user name :email email :activity activity :ts current-ts})) (Thread/sleep rand-interval))))Here’s a sequence diagram representing how the producer generates kafka events:
-

Processing User Messages
This project uses two different Kafka consumers to process each Kafka event:
- Messages Consumer: This consumer consumes each Kafka event and prints out the message payload
- Active Users Consumer: This consumer consumes each Kafka event and stores each user in a Redis store. Every three seconds, it prints out the current list of active users by querying the Redis store.
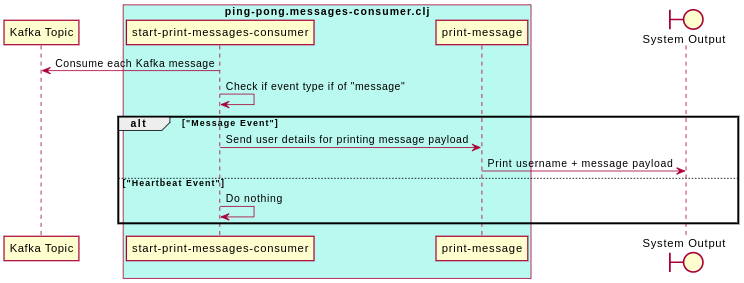
Messages Consumer
This consumer does three things:
- Consumes each event
- Checks if the
activitykey to determine if it is asend-messageevent. - If yes, it prints out the message along with the user name.
Here’s a code-snapshot of this (the entire code can be found here):
(defn print-message
[user m]
(println (format "%s: %s"
user
m)))
(defn start-print-messages-consumer
[]
(let [continue-fn (fn [_] @continue?)
consuming-fn (fn
[value]
(let [{:keys [user message activity]} (ping-pong.utils/keywordise-payload value)]
(when (= activity (:send-message ping-pong.utils/allowed-activities))
(print-message user message))))]
(utils/start-consuming consumer-config
utils/topic
continue-fn
consuming-fn)))
Here’s a sequence diagram of the above:
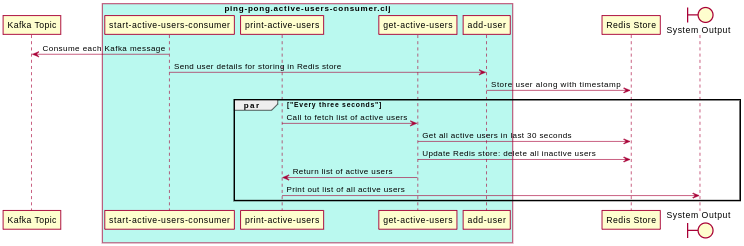
Active Users Consumer
Broadly, this consumer consumes each Kafka event, and stores the user in the Redis store along with the timestamp mentioned in the event payload. The Redis store keeps a timestamp-to-user mapping inside a sorted set.
Every three seconds, the Redis store is queried for fetching the current set of active users. An active user is defined as a user who is seen at least once in the past 30 seconds.
Here’s a snapshot of how this is done (the entire code can be found here)
(defn start-active-users-consumer
[sys]
(let [continue-fn (fn [_] @continue?)
consuming-fn (fn
[value]
(let [{:keys [ts user email]} (utils/keywordise-payload value)]
(add-user sys user email ts)))]
(ping-pong.utils/start-consuming consumer-config
utils/topic
continue-fn
consuming-fn)))
(defn print-active-users
[]
(while @continue?
(let [active-users (get-active-users)]
(if (empty? active-users)
(println "No Active Users...")
(do (println "Active Users:")
(run! #(print (str % ", ")) active-users)
(println "\n---"))))
(Thread/sleep 3000))
(println "----xx---"))
Here’s a sequence diagram of the above:
Tracking Active users
The system relies on Redis to store active users. Specifically, a sorted set is used for storing users. In a sorted set, entities are sorted on the basis of their respective scores. In the present case case, the event time-stamp is the score.
(def store "sorted:users")
(def jedis (JedisPooled. "localhost" 6379))
(defn add-user
[username email score]
(let [user (format "%s::%s" username email)]
(.zadd jedis store (double score) user)))
Thus, every time we need to fetch active users, we can query the sorted set in Redis, by using zrangeByScore where the min score is the cutoff timestamp (i.e., 30 seconds prior to the current time-stamp) and the max score is the current timestamp.
Importantly, while fetching the list of active users, it is important to clean up redundant data, i.e., all users with a score less than the cutoff timestamp.
(defn get-active-users
[]
(let [curr-ts (double (System/currentTimeMillis))
cutoff-ts (double (- curr-ts 30000))
active-users (.zrangeByScore jedis store cutoff-ts curr-ts)]
;; Remove users who were active before the cutoff time-stamp
(.zremrangeByScore jedis store Double/NEGATIVE_INFINITY (dec cutoff-ts))
(map #(first (cs/split % #"::")) active-users)))
Importance of passing event timestamp
Notably, we are using the time-stamp value recorded in the Kafka event (i.e. event timestamp), while pushing a user in the redis store. This may seem redundant: we can use the current time-stamp at the time of consuming the events to do this (i.e. processing timestamp). This will reduce the payload of the kafka event.
However, relying on processing timestamp may lead to inconsistencies if the consumer dies in the middle of consuming events. In such an event, there will be a gap before consumption can resume. When the consumer resumes comsumption, it will start with consuming the pending events. Many of these events would be stale events. Without the event timestamp recorded in the event payload, all these events will be considered as “new” events. However, by relying on the event time-stamp, the consumer can easily detect stale events and reject them as inactive.