Understanding: Log-Structured Merge Trees
In this post, I am listing down my understanding of Log-Structured Merge Trees (LSM Trees, in short), based on my reading of the first part of Chapter 3 of ‘Designing Data-Intensive Applications’ by Martin Kleppmann.
TLDR
-
An LSM tree-backed storage engine comprises of an in-memory data-structure, called a mem-table. Every write operation is done on this mem-table. This data-structure ensures that keys are stored in a sorted manner, irrespective of the write pattern.
-
Once the size of this data-structure reaches a given threshold, its contents are written to a file on disk (called a log). As the mem-table stores data in a sorted manner, the log file also contains keys in a sorted manner. Note that log files are immutable - each time you write to a file you either append or write to a new log file.
-
In the background, multiple log files are merged and compacted (i.e. removal of duplicate keys) from time to time.
-
Read path: Reads are done in the following manner: search for a key in the mem-table, then on the latest log file, all the way up to the oldest log-file.
-
Write path: Directly update the mem-table. This is one of the reasons LSM trees are so fast.
-
In addition to the memtable, we also keep an in-memory hash-index of keys, for each log, where each key maps to the on-disk location of the key. Because keys are always sorted, we keep a sparse index.
Detailed Notes
Simple k-v store: The Log
-
The simplest form of a key-value datastore would involve a text file (often called a ‘log’), where each line consists of a key-value pair (separated by a comma)
-
For writing to this data store, i.e., creating a new pair or updating an existing pair, we simply append the key-value pair at the end of that log
-
For reading, we need to scan the entire log, by looking for the given key. If two keys are found, the latest key-value pair will be considered. This is because we never overwrite an existing entry in the log: we simply append at the end of the log.
-
This kind of data-store has very fast writes - O(1) as appending to a file is a very cheap operation. Conversely, look-ups are very painful - O(n), where n is the number of records in the log.
-
Important: we never write existing data present in the log file.
Using an in-memory hash-map to improve performance
-
To improve the look-up operations, we can make use of indexes, which store additional meta-data about the records and act as a “signpost”.
-
Essentially, while doing writes, we store this additional metadata in addition to the appending operation. Thus, adding any kind of index will slow down write operations, but will also speed up read operations. Because the effectiveness of an index is dependent on the patterns of read queries, an application developer needs to manually add indices - they don’t come set by default.
-
One common index is to use an in-memory hash-map, which contains all the keys of the actual data-store, and these keys map to the on-disk location of that key in the data store. This makes look-ups far more efficient: given a key, we can use the in-memory data-structure to find the location of the key on the disk (as opposed to scanning the whole log file).
-
One limitation of this in-memory hashmap approach is that the total number of keys is limited by the finite size of RAM - since all keys of the data-store needs to be stored in the in-memory data-structure. Given this limitation, this kind of data-store is very useful in cases where the number of keys are finite but the values are updated frequently.
-
We also need to consider the situation where the log file becomes so large that its size becomes comparable to that of the disk. To overcome this, we can break the log file into segments, such that, the moment the log reaches a given size, we make subsequent writes on a new segment file.
Merger and compaction of logs
- We can use compaction on existing segment files, ie, removing duplicates between two or more existing segments. This can reduce the overall size of the data-store as we get rid of duplicate keys (which are really just redundant data).
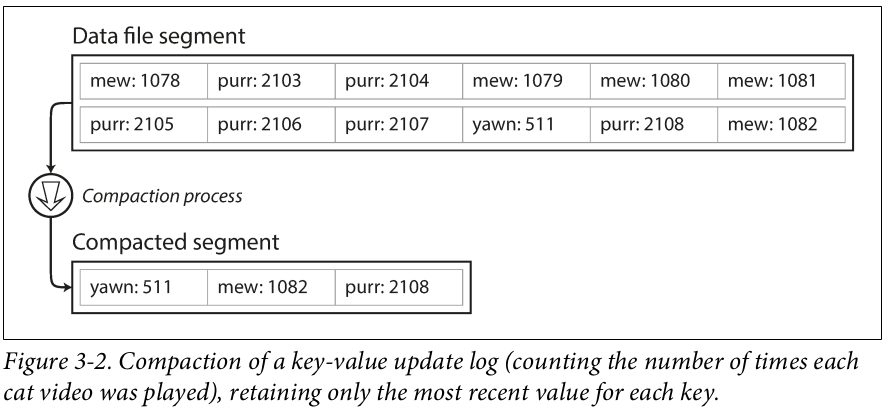
Source: Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
-
Since compaction can make segments smaller, we can merge two or more segments into one new segment.
-
This compaction and merging of frozen segments can happen asynchronously (in the background), while new writes take place on a new segment and reads use existing segments.
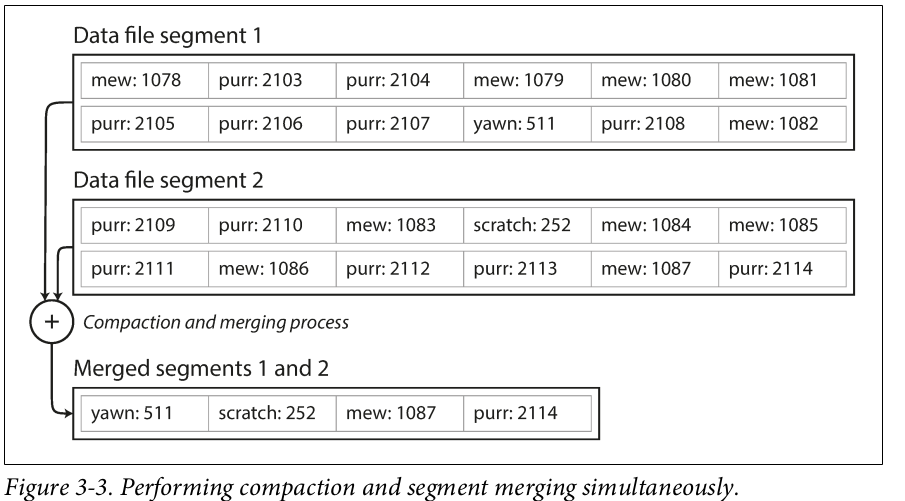
Source: Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
-
We keep separate in-memory hash-map indices for each segment. When we need to look up a given key, we start with the hash-map of the latest segment and go all the way back to the oldest segment, stopping the moment we find the key we are looking for. Deleting operations need to be dealt with separately for this kind of data-store: when a key is deleted, a special value should be stored against it on the log file.
-
If the database crashes, we will need to re-construct the in-memory hash-maps of each segment from scratch. This limitation can be overcome, if we keep a copy of the in-memory data-stores on a separate log of operations on the disk.
-
Another limitation of this append-only data-store is that it is not efficient for making range queries.
SSTables and LSM-Tree
-
In an append-only data-store, writes are not made in any particular order: they are made sequentially.
-
But we can also store the key-value pairs in a sorted manner (i.e. sorted by keys), while storing in the segment logs. This format is called Sorted String Tables.
-
For a given segment log, a single key appears only once (this can be easily achieved by compaction, as seen above).
-
SSTables have several advantages over simple append-only databases.
-
First, merging segments is possible, even when the size of the segment files exceed the available memory. While merging multiple segments, we start with the first key of each segment file, and write the key with the lowest value, and so on (similar to mergesort algorithm). If two or more segments contain the same file, we pick from the segment which is more recent (as that’s how segments are created).
-
Second, we no longer need to maintain the file location of each key of the data-store. If we know the location of “handbag” and “hardwork”, we will know that the location of “handsome” will be in between these two locations. So we can jump to the offset of “handbag” and scan till we come across “handsome”. Thus, we no longer need to keep an in-memory map of all the keys of the data-store.
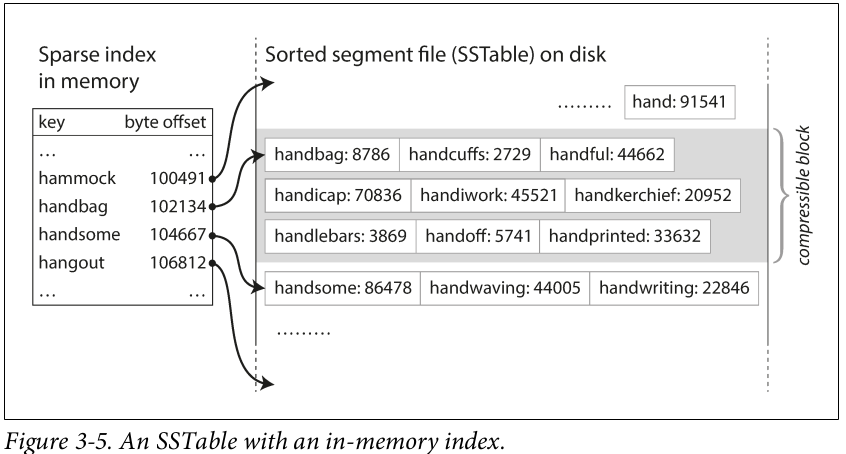
Source: Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
-
How to store keys in a sorted manner, in the first place? We can use an appropriate in-memory tree data-structure (such as a red-black tree) which allows us to write data in any order, but which stores them in a sorted manner. Thus, when a write operation is made, the key-value pair is stored in an in-memory data-structure which ensures this sorting property.
-
Once this data-structure passes a given threshold, we write the key-value pairs to a segment file in a sorted manner, thereby creating SSTables.
-
For a read operation, we first search for the key in the memtable, then to the most recent SSTable segment file, and so on.
-
One downside: in case of a crash, the most recent keys in the memtable will be lost. To fix this, we take a backup of the memtable in a separate file - which can simply be an append-only log file. In effect, each write operation makes two operations, it writes to the memtable and to the back-up append-only log file. The latter is used only for re-constructing the mem-table in case of a server crash. Storage engines which are based on this principle of merging and compacting sorted files are often called LSM storage engines, or, Log-structured Merge-Tree storage engines.
-
In LSM storage engines, look-up operations for non-existent keys are slow: to confirm a key is absent, we need to traverse from the memtable all the way to the oldest segment file. We can use bloom filters, to optimise this, as it can help us in knowing if a key is absent or not.
-
Like the append-only storage engine, we keep in-memory hash maps for each segment file, which stores keys sparsely (ie not every key, but every n keys).
References
- Martin Kleppmann, Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems (O’Reilly Media. 1st Edn.), Chapter 3
- ‘How do LSM Trees work?’,https://yetanotherdevblog.com/lsm/